

We’re thrilled to launch Code Quality Reviews in Corgea, our take on AI code reviews. You’re probably wondering, do we need another AI code review tool? And it’s true, the space is immensely crowded, and believe it’s because it’s underserved.
As we’ve been scaling as a company, we needed a better way to review code ourselves. We use AI in so many ways to generate code, write docs, and produce our changelog, we’re also very weary of it in our mission critical product. Code volume is exploding and AI slop code is being generated. We tried many different code quality products like Copilot, but they didn’t scratch the itch we had. Humans were still the bulk of our quality gate, and when you’re a high velocity startup, you end up missing things.

Most “AI code review” tools do a decent job on obvious issues, but they miss the problems engineers actually care about: multi-file mistakes, framework-specific footguns, and non-trivial correctness/performance issues that depend on intent and context. The other failure mode is noise. If findings bad, teams stop trusting the tool.
As experts in static code analysis, we decided to repurpose all our IP and expertise to build something we wanted. Security scanning is a quality problem, so similar principles applied. Coincidentally, customers approached us to help them replace their existing solutions since they liked our security scanning product. They wanted Corgea to be a one-stop shop for engineering teams to stop slop, whether security or quality related. We felt so strongly about this, we changed the hero message on our landing page from “Ship code not vulnerabilities” to “Ship code not slop”
What we built + why it’s different
We built Code Reviews on the same foundations as Corgea’s security scanning product. That matters because security scanning has a higher bar: it requires multi-file context, deeper code understanding, and higher precision. Enterprises have strict compliance and regulatory requirements on vulnerability scanning, which pushed us to make a great security scanning product that is able detect business logic and authentication vulnerabilities. Companies like Zapier and Yageo use Corgea to do this.
We decided to reuse that bar for code quality, rather than bolting an LLM onto a generic “review this diff” workflow. We picked several design choices to drive the experience.
> ”… their ability to catch common issues in AI-generated applications, including authentication flaws and always-true conditional statements is impressive.”
>
>  >
> James Berthoty - Industry Analyst from Latio
>
> James Berthoty - Industry Analyst from Latio
First, we anchor findings in CWE taxonomy (same as security scanning) to keep feedback focused, reportable and consistent. As far as we know, we’re the only company in the space that does this, and it was a pretty big debate internally, but in our testing we know this helps our models (and the humans reading output) converge on recognized issue types rather than vague advice.

Second, we leverage the same security scanning pipeline (albeit repurposed) to increase determinism, focus on context and elimination of false positives and noise in the scanning process. We wanted to end the endless “review-spiral” that systems like Copilot had. Copilot finds things in the PR -> You fix -> You commit -> Copilot runs again and finds more things -> you fix -> etc. What’s worse is that it does this for code the developer may have not touched. This annoyed us so much we ended up turning off Copilot in our pull requests.
Third, we enforce a high-confidence threshold (≥ 90% confidence) and a false positive detection layer so results stay actionable. That means fewer “maybe” findings and less time spent debating whether the tool is hallucinating.
Finally, we treat remediation as part of the workflow, not a separate task. When a finding is fixable, Code Reviews can propose changes using the same automated remediation capability Corgea already uses for security. You still review the diff, but you don’t have to start from a blank file.
Here’s our the same security scanning pipeline that we repurposed for code review that was described in our white-paper.
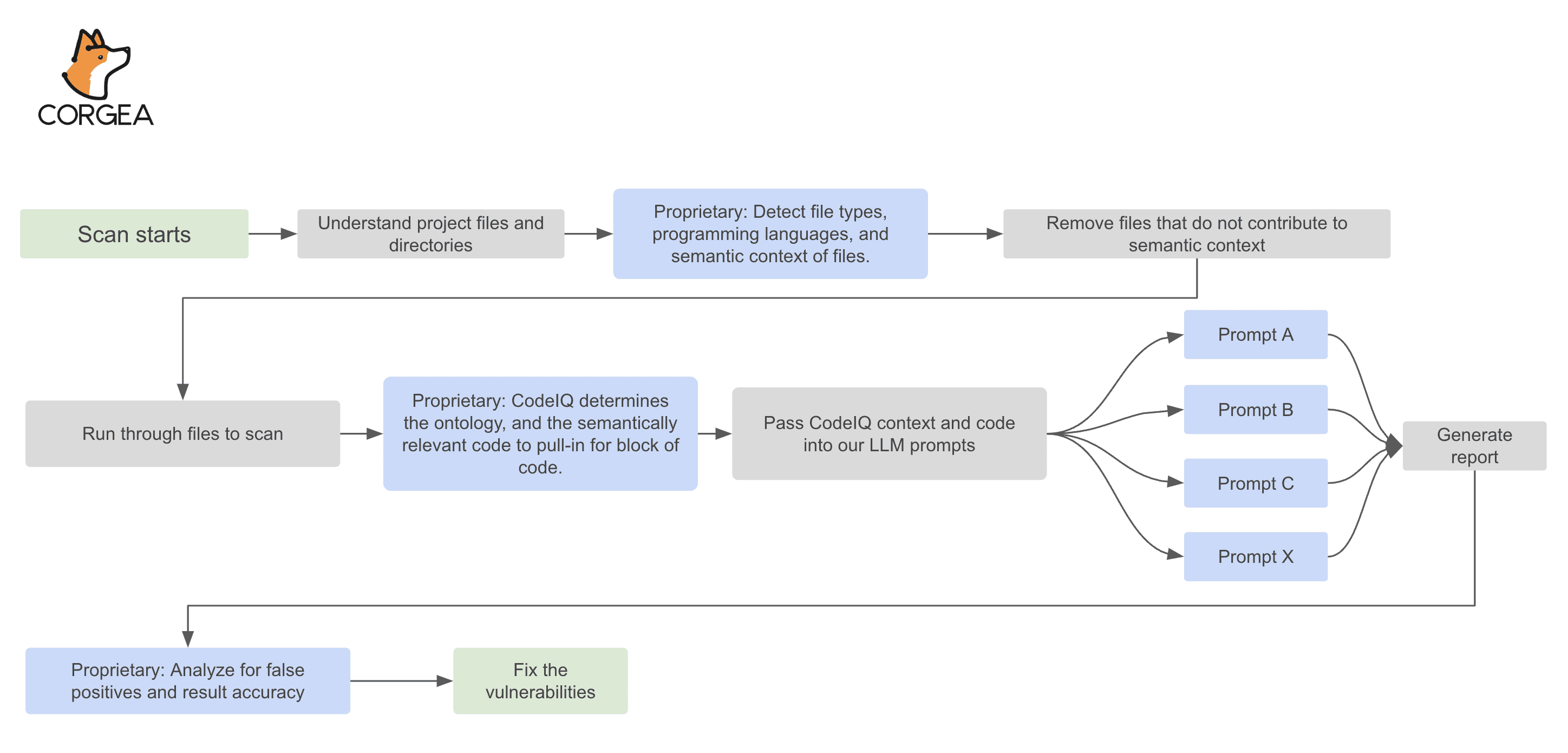
How it works (end-to-end flow)
After you connect your repo (GitHub, GitLab, Azure DevOps, or Bitbucket), Corgea runs a code quality scan against the codebase during the pull request. The scan starts with standard analysis to understand file structure, language and framework patterns, and where the code’s boundaries are. Then the review layer applies deeper reasoning to identify code quality issues that are harder to capture with rules alone, things like brittle logic, inefficient patterns in hot paths, error-handling gaps, or maintainability problems that span multiple files. The same PR-first workflow is part of Corgea developer experience.
On output, each finding points to specific lines and provides concrete reasoning for why it matters, categorized into a CWE where applicable and assigned a severity. We also intentionally do not want to focus entire classes of “review noise.” Style and formatting bikeshedding is not the goal here. And security vulnerabilities are not mixed in, those are handled by Corgea’s security scanners so that quality reviews stay scoped and readable.
When a finding is something we can confidently fix, Code Reviews can generate a patch. The point isn’t “auto-merge AI changes.” The point is accelerating the boring parts: creating a safe diff that follows common patterns, so a developer can review and adjust instead of rewriting the same refactor by hand.
An Example
This is an example straight from the Corgea platform. The code duplicates token parsing logic using Authorization.startswith("Bearer ") and split(" ")[1] in multiple functions like add_game. This repetition risks inconsistent token extraction across endpoints.
-
Duplicated parsing logic in “add_game”, “delete_game”, “update_profile” makes updates error-prone and inconsistent.
-
Higher maintenance cost as bug fixes or changes to token extraction must be applied in multiple places.
-
Code duplication reduces readability and clarity, making it harder for team members to understand shared authentication behavior.
Keep in mind, there’s a security vulnerability here. The Bearer tokens aren’t being validated here, but that would be a separate finding from our security scanner. We’re trying to illustrate the violation of the DRY principle here.
@app.post("/games")
def add_game(game: VideoGame, Authorization: Optional[str] = Header(None)):
if not Authorization:
raise HTTPException(status_code=401, detail="Authorization header required")
if not Authorization.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Invalid Authorization header format")
token = Authorization.split(" ")[1]
...
for user in users:
if user.token == token:
if user.is_admin:
video_games.append(game)
return {"message": "Game added"}
else:
raise HTTPException(status_code=403, detail="Not authorized")
raise HTTPException(status_code=401, detail="Invalid token")
@app.post("/admin/delete_game")
def delete_game(game_id: int, Authorization: Optional[str] = Header(None)):
if not Authorization:
raise HTTPException(status_code=401, detail="Authorization header required")
if not Authorization.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Invalid Authorization header format")
token = Authorization.split(" ")[1]
...
for user in users:
if user.token == token and user.is_admin:
for i, game in enumerate(video_games):
if game.id == game_id:
deleted_game = video_games.pop(i)
# No logging of the deletion action
return {"message": f"Game '{deleted_game.title}' deleted"}
raise HTTPException(status_code=404, detail="Game not found")
raise HTTPException(status_code=403, detail="Not authorized")
@app.post("/update_profile")
def update_profile(username: str, email: str, Authorization: Optional[str] = Header(None)):
if not Authorization:
raise HTTPException(status_code=401, detail="Authorization header required")
if not Authorization.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Invalid Authorization header format")
token = Authorization.split(" ")[1]
...
for user in users:
if user.token == token:
user.username = username
user.email = email # Assuming 'email' field exists in User model
return {"message": "Profile updated"}
raise HTTPException(status_code=401, detail="Invalid token")Corgea suggested to fix it by abstracting an this duplicative code. Encapsulating repeated Authorization header validation and token extraction into a single function improves code reuse, readability, and maintainability by centralizing authentication logic.
-
“get_bearer_token_from_auth_header” function centralizes token extraction and validation logic, reducing duplicated code across the codebase.
-
This abstraction improves readability by replacing inline validation with a clear, descriptive function call.
-
Consistent error handling for missing or malformed headers is enforced in one place, simplifying future updates or fixes.
By isolating this logic, testing and debugging authentication-related issues become easier and less error-prone.
def get_bearer_token_from_auth_header(auth_header: Optional[str]) -> str:
if not auth_header:
raise HTTPException(status_code=401, detail="Authorization header required")
if not auth_header.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Invalid Authorization header format")
return auth_header.split(" ")[1]What you get (what success looks like)
If you’ve tried other code review assistants, you’ve probably seen two extremes: either shallow feedback that duplicates your linter, or speculative feedback that generates churn. You’ve probably experienced this meme.

Code Reviews aims for a narrower, higher-signal lane. You should expect fewer false positives because we only emit findings above a confidence threshold. You should also expect less review friction because we go beyond subjective style guidance and focus on issues with clear engineering impact. And you should expect broader coverage than rule-only tools because the system is designed to reason about code in context, not just match patterns in a single file.
Over time, you also get a consistent way to bucket and prioritize issues (via CWE mapping and severity), which makes it easier to run engineering-quality “campaigns” the same way teams already run security work: pick the important classes, work them down, and measure progress.
Limits / non-goals (tradeoffs we made)
Code Reviews is not meant to be your formatter or your style policy. If what you want is enforcing whitespace, naming, or opinionated conventions, your linter/formatter is the right tool and will stay faster and more deterministic.

It’s also not a vulnerability scanner. We intentionally exclude security vuln classes from this feature so the output stays scoped; use Corgea’s security scanning for that. Finally, remediation proposals are not meant to bypass review. They are meant to reduce the cost of fixing obvious issues. Engineers should still validate correctness, edge cases, and fit with team conventions.
Who it’s for / who it’s not
It’s for developers and engineering teams who want code quality reviews that focus on substantive issues like correctness, maintainability, and performance. It’s also for AppSec and engineering leads who want consistent categorization and a workflow that looks familiar (scan → review → prioritize → fix).
Conclusion
Code quality tools usually fail in one of two ways: they’re shallow (basically a linter), or they’re noisy (lots of “maybe” comments that don’t survive review). Corgea’s Code Reviews is built to sit in the middle: deeper, multi-file reasoning with a precision bar high enough that engineers can actually trust what shows up.
Try it now or book a demo: https://www.corgea.app/registration/