

Static Application Security Testing (SAST) is one of the most important tools in the AppSec arsenal, and has moved through three clear eras over the last +25 years. Each era maps to how software was built and shipped at the time. Each wave has tried to fix the pain of the previous one, and has made considerable progress but has struggled through certain limitations. This is a practical look at those waves and what they imply for teams making choices today.
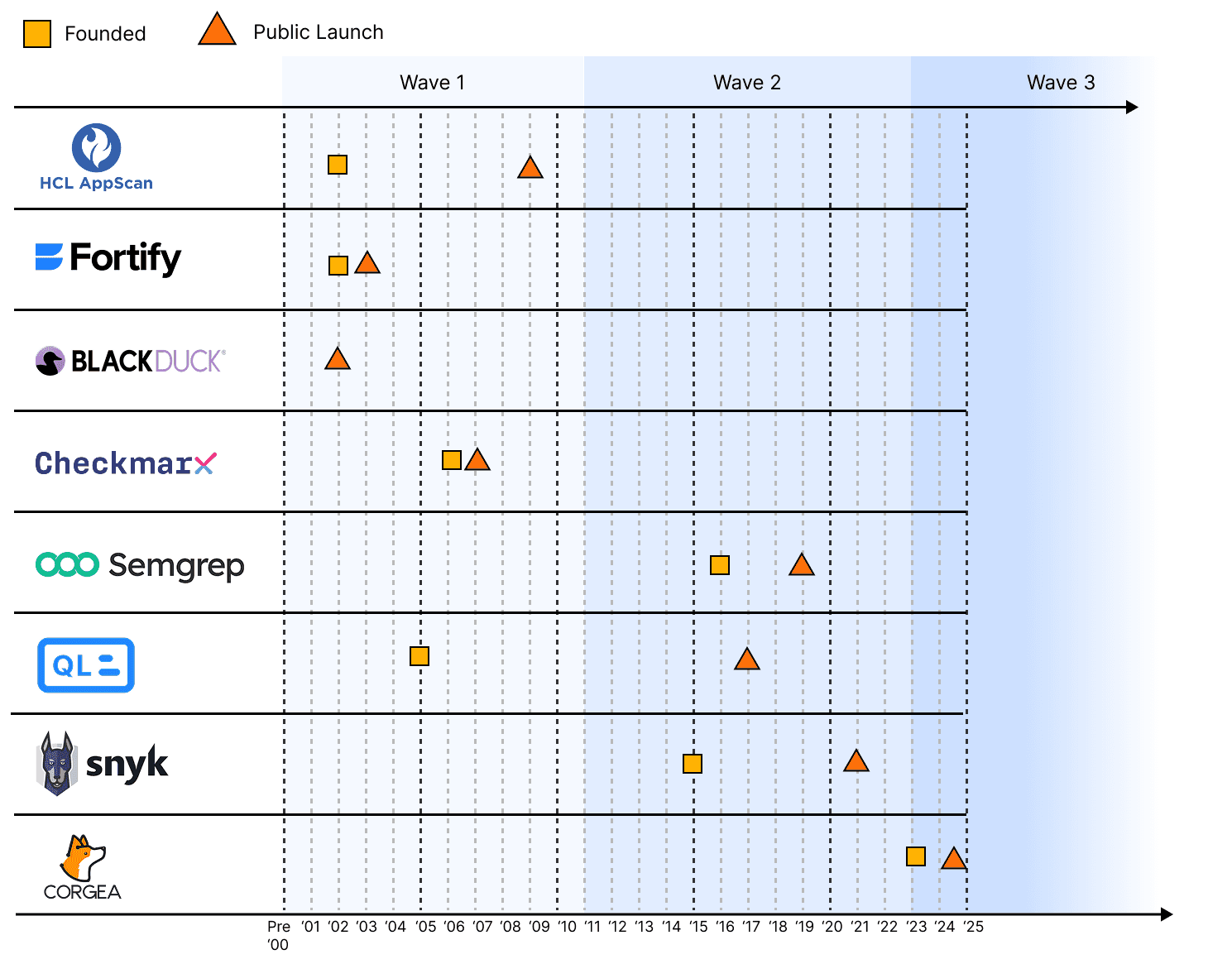
Wave 1: Enterprise pioneers (2000s)
The first generation of SAST arrived in the early 2000s when secure coding was barely on the radar. They were true pioneers in the application security space. Their goal was clear and cutting-edge: Can tools find vulnerabilities in code?
To shape the picture better, a lot had happening in the early 2000s to push this forward. SOX (2002) pushed public companies toward stronger internal controls, elevating software risk to the boardroom. PCI DSS v1.0 (2004) arrived soon after, pressuring anyone processing card data to prove secure development practices. OWASP published its first Top 10 in 2003, giving teams a shared language for web risks. These forces helped create the first generation of enterprise SAST.

Who and what: Coverity, Fortify, Checkmarx, and the Ounce Labs technology later branded AppScan Source. These products established commercial static analysis and made it part of enterprise governance.
Strengths then:
-
Proved large-scale static analysis was possible.
-
Delivered reporting auditors could use.
Trade-offs that surfaced:
-
Long scan times that didn’t fit tight release cycles.
-
High triage cost due to noisy results.
-
Rigid, on-prem deployments that slowed updates.
-
Language coverage that grew slowly beyond C/C++/Java.
These tools became fixtures in large organizations because they matched the era’s release cadence and governance needs, even if they were heavy to run. Despite all this, these products entrenched themselves in Fortune 1000 organizations. Checkmarx still claims 40% of the Fortune 100 today. Legacy dies hard.
Wave 2: Developer-first and cloud delivery (2010s)
By the mid-2010s, developers had had enough. A new wave of tools promised faster scans, cloud delivery, and a focus on developer experience. With more companies writing code, and the adoption of cloud technologies, new competitors came into the market.

Who and what: GitHub-integrated CodeQL, Semgrep’s open-source rule engine, and Snyk Code’s developer-oriented workflow. The pitch shifted from “prove compliance” to “unblock developers.”
What improved:
-
Speed and placement: CI-friendly runtimes and IDE feedback made findings more actionable.
-
Customization: Rule registries and reusable query packs helped teams tailor detection.
-
Usability: Results were framed for code owners, not only security reviewers.
What remained hard:
-
Rule debt: Cutting noise meant writing and maintaining rules/queries, which requires expertise.
-
Limited semantics: Pattern- and data-flow-centric approaches struggled with business-logic issues and cross-service authorization gaps.
Wave 2 made SAST more usable in modern pipelines but left deep reasoning, false positives and maintenance cost largely unsolved. We’re observing that this wave is moving towards AI-powered SAST (not native) where LLMs are assisting in triaging and auto-remedaition.
Wave 3: AI-native SAST (2024 → )
Gen‑AI coding assistants went mainstream; surveys show 62% of developers already use AI tools at work (source). Security orgs are now expected to secure human‑ and AI‑generated code at the same speed.

What’s different: 2024 marked a turning point. New entrants like Corgea (white-paper), and a wave of academic research (1, 2) showed what happens when you don’t just add AI to SAST, but rebuild it around AI from the ground up. Unlike the previous wave that is adopting AI to become AI-powered, this one is about AI-native solutions where LLMs are at the forefront. AI-native systems are built to reason about code, not just match patterns. They combine large language models with program analysis to follow flows across files, frameworks, and services, and to explain why something is risky in plain language.
Expected outcomes:
-
Better signal: More context per finding and fewer “technically true, practically irrelevant” alerts.
-
Logic and auth coverage: Ability to flag missing or broken authorization, misuse of domain rules, and framework-specific pitfalls that DSL rules rarely capture.
-
Explainable fixes: Suggestions that cite paths and constraints, so maintainers can verify and merge with confidence.
-
Stronger evidence: Artifacts that map to secure-development frameworks and audits, not just a list of CWE IDs.
Constraints to plan for:
-
Cost management: Scanning monorepos with LLMs needs the right strategies and hybrid analysis to control spend.
-
Repeatability: Policies, seeding, and snapshotting are important so the same PR yields consistent results.
Where Corgea fits:
Corgea is in this third wave. The product is designed to feel like code review from an AppSec engineer with semantic understanding first. It integrates in PRs and CI, produces explanations tied to actual code paths, and generates evidence that aligns with modern secure-development requirements. It’s is a new generation pioneering a way way to reduce noise, cover logic paths rules don’t model well, and give developers faster, clearer feedback.
How to evaluate SAST in 2025
Use a short, testable checklist:
-
Coverage depth: Does the tool find broken or missing authorization, cross-file data flows, and framework-specific issues without hand-writing dozens of rules?
-
Noise profile: What’s the reviewer acceptance rate in your codebase over a 2–4 week trial? Track accepted vs. dismissed findings per repo.
-
Maintenance load: How much ongoing rule or query work is required to keep precision acceptable? Who owns it?
-
Developer experience: Are explanations specific, linked to paths, and easy to verify? How fast is feedback in PRs and CI?
-
Runtime cost: What levers exist to manage cost (selective scanning, caching, hybrid symbolic+neural passes)?
-
Governance: Can the tool map results and workflow evidence to your policy framework (e.g., internal SDLC controls, customer audits), not just produce lists?
The takeaway
-
Wave 1 made static analysis real for enterprises.
-
Wave 2 made it fit modern developer workflows.
-
Wave 3 changes the unit of value from “a matched rule” to “a defensible code review with context.”
If you’re choosing tools now, start with a small, representative pilot. Measure acceptance rates, fix time, and policy evidence quality; not just the number of findings. Keep what reduces real risk with the least process overhead, and phase out what doesn’t.