

Most AppSec teams are underwater. Codebases are growing faster than security headcount, scanner output is a firehose of noise, and developers treat security findings like spam. AI application security is the first real attempt to change that equation, not by adding more tools, but by making the ones you have smarter about what matters and what doesn’t. This guide breaks down how AI is actually being applied across the AppSec lifecycle in 2026, where it works, where it falls short, and how to adopt it without blowing up your existing workflows.
1. The AppSec Scalability Crisis
The math doesn’t work. A typical enterprise runs developer-to-security ratios somewhere around 100:1. Some orgs are closer to 200:1. Meanwhile, the attack surface keeps expanding: microservices, APIs, third-party dependencies, infrastructure-as-code, client-side SPAs, mobile backends. Every new repo is another thing that needs scanning, triaging, and fixing.
Traditional tools haven’t scaled with this reality. A SAST scanner that produces 500 findings per scan isn’t “thorough.” It’s unusable. When 70-90% of those findings are false positives or low-risk noise (a commonly cited range across industry surveys, though exact numbers vary by tool and codebase), developers stop looking. Alert fatigue isn’t a buzzword; it’s measurable in ignored Jira tickets and skipped CI gates.
The bottleneck isn’t detection. We have plenty of scanners. The bottleneck is triage and remediation at the speed software actually ships. That’s the gap AI is starting to close.
2. What Is AI Application Security? Defining the Landscape
AI application security refers to applying machine learning, large language models, and related techniques across the software security lifecycle: detection, prioritization, remediation, and policy enforcement. It’s broader than bolting a model onto a traditional static application security testing scanner.
The landscape includes:
-
ML-based detection - Pattern classifiers and neural networks trained on vulnerability databases (NVD, CWE corpora, open-source commit histories) to identify insecure code patterns.
-
LLM-powered code analysis - Large language models that reason about data flow, business logic, and developer intent to distinguish real vulnerabilities from noise.
-
Automated remediation - Systems that generate, validate, and propose fixes as pull requests rather than just flagging problems.
-
Intelligent triage - Models that score and prioritize findings based on exploitability, reachability, and blast radius, not just CVSS severity.
The key distinction from prior-generation “smart scanning” is depth of context. Earlier heuristic approaches matched syntax patterns. LLM-based code reasoning can trace a user input through three service boundaries, understand that it gets sanitized at layer two, and suppress the false positive that every regex-based scanner would flag.
3. Key Use Cases: Where AI Delivers Real Value in AppSec
Here’s where AI appsec is actually producing results today, ordered roughly by maturity and adoption.
3.1 Static Analysis False-Positive Reduction
This is the highest-ROI use case right now. AI models re-analyze SAST findings with deeper code context (data flow, control flow, framework-specific sanitization patterns) and suppress findings that aren’t actually exploitable. Teams commonly report 60-80% reductions in actionable alert volume, though results depend heavily on the baseline scanner and codebase. The practical effect: developers actually look at what’s left.
Here’s an example of a false positive on an SQL injection:
> The SQL on 23 uses username and password which are initialized as empty strings on 20-21 and the formatted query is executed immediately, so no attacker-controlled input reaches that sink. User-controlled values are assigned later (e.g. if 'username' in request.form / username = request.form['username'] at 86-87), so the specific call on 23 cannot be exploited as shown.
@app.route('/', methods=['GET', 'POST'])
def index():
output = ''
# 1 - SQL Injection
db = sqlite3.connect("tutorial.db")
cursor = db.cursor()
username = ''
password = ''
try:
cursor.execute("SELECT * FROM users WHERE username = '%s' AND password = '%s'" % (username, password))
except:
pass3.2 Automated Vulnerability Remediation
Instead of handing a developer a CWE-89 (SQL Injection) finding and a link to OWASP, AI remediation tools generate a concrete fix in the context of the actual code. The pipeline typically looks like:
-
Vulnerability ingestion from SAST/DAST/SCA scanners
-
Code context retrieval around the flagged location (file, function, dependencies, framework conventions)
-
LLM fix generation producing a patch that addresses the root cause
-
Static validation to confirm the fix compiles, doesn’t introduce regressions, and actually resolves the finding
-
PR creation with an explanation of what changed and why
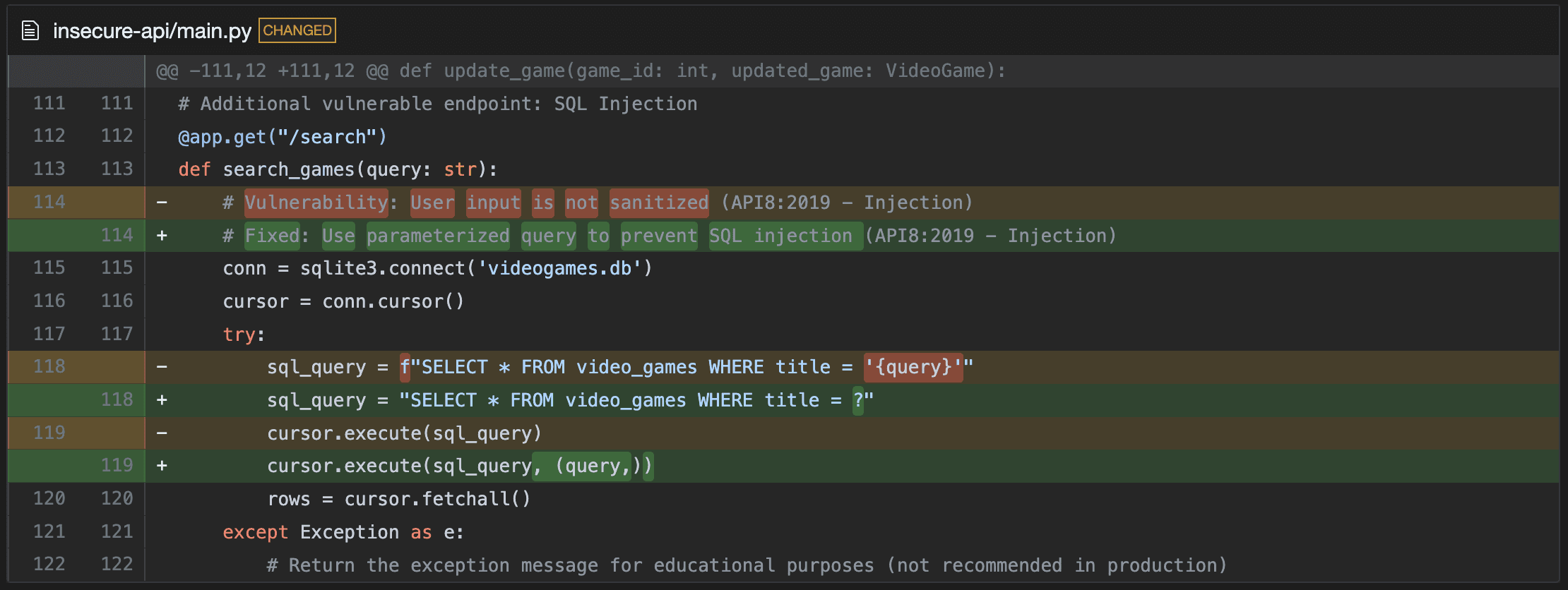
This is the architecture behind tools like Corgea, which ingests findings from existing scanners and produces validated fix PRs, closing the gap between “finding identified” and “finding resolved.”
3.3 Intelligent Threat Modeling
AI-assisted threat modeling tools analyze architecture diagrams, IaC configs, or code structure to generate initial threat models (STRIDE-based or custom). They’re not replacing a seasoned threat modeler, but they reduce the blank-page problem and make it practical to threat-model more frequently, especially for teams that historically only did it once per major release.
3.4 Security Code Review Copilots
AI-powered review bots that comment on PRs with security-relevant observations. The good ones go beyond “this looks like SQL injection” and explain the data flow path. The bad ones are noisy annotation machines that developers mute within a week. The difference usually comes down to whether the model was fine-tuned on security-specific data or is just a general-purpose LLM with a security prompt.
3.5 Anomaly Detection in Runtime
ML models trained on normal application behavior (request patterns, API call sequences, resource usage) that flag deviations in real time. This sits more on the detection/response side than the development side, but it’s part of the broader AI security tools ecosystem. Useful for catching exploitation of zero-days or business logic abuse that signature-based WAFs miss.
3.6 Supply Chain Risk Scoring
AI models that evaluate open-source packages beyond known CVEs: analyzing maintainer behavior, commit patterns, dependency depth, and code changes between versions to flag supply chain risk before a package enters your lockfile. Think of it as integrating AI remediation with Semgrep findings or SCA output to cover the full dependency picture.
4. The Technology Stack Behind AI-Powered Security
Understanding what’s under the hood helps you evaluate vendor claims and set realistic expectations.
Pattern Classifiers for Vulnerability Detection
Traditional ML classifiers (random forests, gradient-boosted trees, neural networks) trained on labeled datasets of vulnerable vs. safe code. These work well for known vulnerability classes with lots of training examples (SQLi, XSS, buffer overflows) but struggle with novel patterns. Training data comes from sources like the National Vulnerability Database, CWE entries, open-source fix commits, and curated security datasets.
LLMs for Code Understanding and Fix Generation
Large language models (ChatGPT, Claude, Llama, and other proprietary fine-tuned variants) are where the step change happens. Unlike pattern classifiers, LLMs can:
-
Follow data flow across files and function boundaries
-
Understand framework-specific conventions (e.g., knowing that Django’s ORM parameterizes queries by default)
-
Generate syntactically and semantically correct patches
-
Explain findings in natural language that developers actually read
The tradeoff is cost and latency. Running an LLM over every finding in a 500-alert scan takes real compute time and API spend. Most tools batch and prioritize.
For a concrete example of how automated remediation works end-to-end, the pipeline involves ingesting scanner output, retrieving surrounding code context, generating candidate fixes via LLM, validating those fixes against static analysis rules, and opening a PR with the result.
NLP for Policy-to-Code Mapping
Natural language processing models that parse security policies, compliance requirements, or internal coding standards and map them to enforceable code rules. Still early-stage, but the direction is: write a policy in English, rather than an archaic format.
Reinforcement Learning for Fuzzing
RL-guided fuzzers that learn which input mutations are most likely to trigger new code paths or crashes. This produces higher coverage with fewer iterations than purely random or grammar-based fuzzing. Google’s OSS-Fuzz has published work in this area.
5. AI-native SAST vs. Traditional SAST: A Concrete Example
Let’s make this tangible. Consider a mid-size Java monolith with roughly 200K lines of code.
Traditional SAST scan (e.g., a commercial tool with default rulesets):
-
Produces ~200 findings
-
~40 are critical/high severity based on CWE classification
-
Developer reviews find that roughly 150 are false positives or duplicates
-
Maybe 30-50 are actionable
-
Triage takes the security team ~2 weeks
-
Developers fix maybe 15 before the next sprint priority takes over
AI-native SAST:
-
Different initial 200 findings ingested as business logic and auth are detected
-
AI model analyzes data flow context, identifies framework-specific sanitization, deduplicates across call chains
-
Output: ~30 prioritized findings with exploitability scores and blast radius estimates
-
25 come with auto-generated fix PRs that pass static validation
-
Triage takes 2 days instead of 2 weeks
-
Developers merge 12 fixes same sprint, manually address 10 more
The scanner changed, and the intelligence layer on top made its output usable. For a deeper dive into specific tooling options, see our comparison of AI-powered SAST tools.
The important framing: AI isn’t replacing SAST, DAST, or SCA. It’s an augmentation layer that makes existing tools more effective by solving the triage and remediation bottleneck.
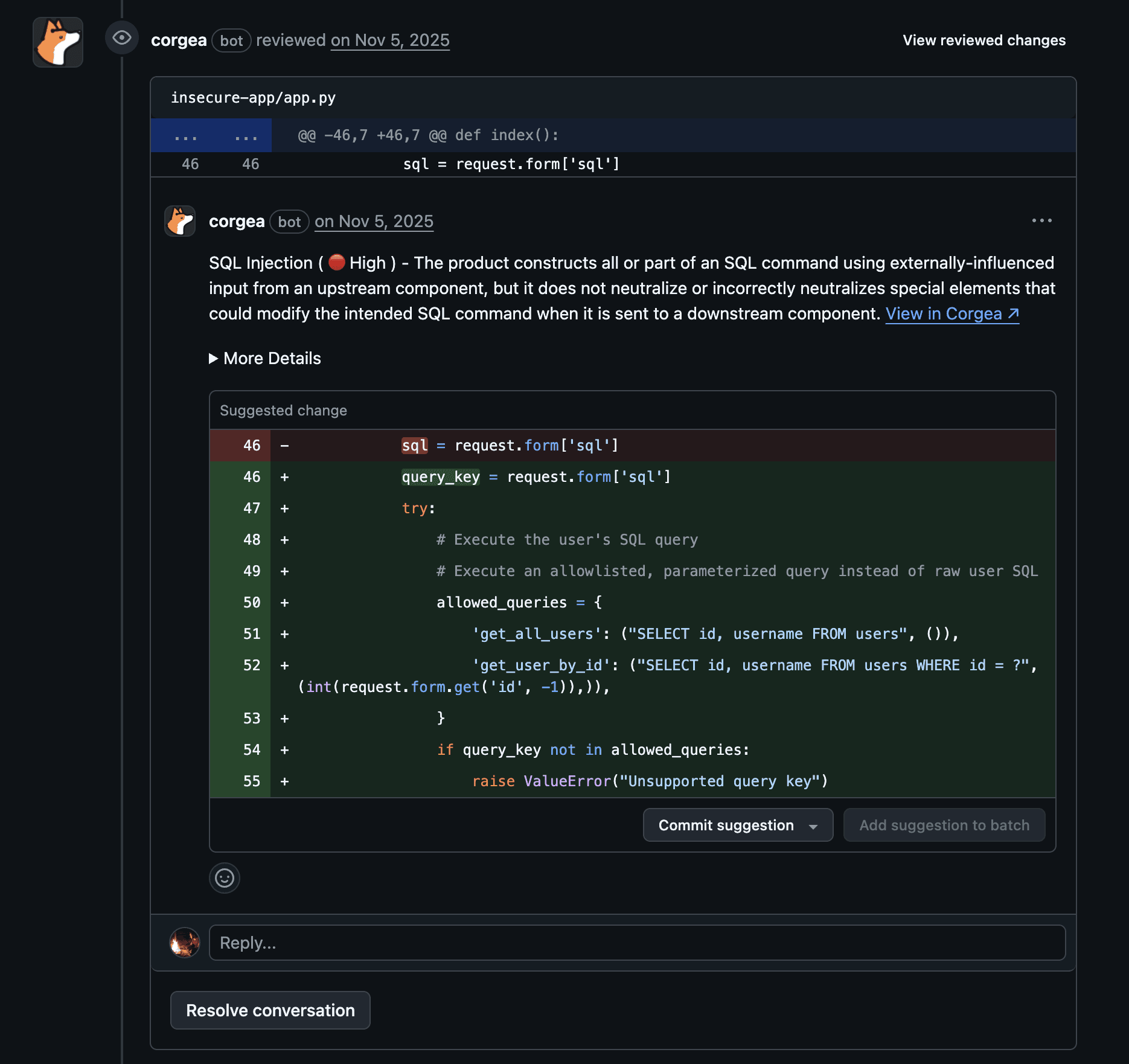
6. Evaluating AI Security Tools: What to Look For
Not all AI security tools deserve the label. Here’s a practical evaluation framework.
Model Transparency
Can the vendor explain what model(s) they use and how they reach conclusions? “AI-powered” with no further detail is a red flag. You want to understand whether you’re getting a fine-tuned LLM, a pattern classifier, or a retrieval-augmented generation (RAG) system. This matters because each approach has different failure modes.
Training Data Provenance
What data was the model trained on? Models trained exclusively on public vulnerability databases (NVD/CWE) will have blind spots for proprietary frameworks, internal libraries, and novel vulnerability classes. Ask whether the tool learns from your codebase over time (and what the privacy implications are).
False-Positive Benchmarks
Ask for benchmarks, ideally on datasets similar to your stack. “AI reduces false positives” is meaningless without numbers and methodology. Good vendors publish results against OWASP Benchmark or NIST SARD, or can run a proof-of-concept against your own codebase.
Integration Depth
An AI security tool that requires developers to log into a separate dashboard is dead on arrival. Evaluate:
-
IDE plugins for real-time feedback during coding
-
CI/CD pipeline stages (GitHub Actions, GitLab CI, Jenkins) for scan-time augmentation
-
Ticketing system webhooks (Jira, Linear, GitHub Issues) for finding management
-
SARIF export for interoperability with other tools
-
PR/MR comments for developer-native remediation workflows
Remediation Accuracy
If the tool generates fixes, what’s the accuracy rate? A fix that introduces a new bug is worse than no fix at all. Look for tools that validate generated patches against static analysis, run unit tests, or at minimum surface confidence scores.
Vendor Lock-in Risks
Does the tool sit as a layer on top of your existing scanners, or does it replace them? Augmentation layers (consume SARIF/JSON from any scanner, add intelligence) are lower risk than tools that require you to rip out your current SAST/DAST stack.
Conclusion
AI application security isn’t magic, and it’s not hype. It’s a practical response to a math problem: too many findings, too few people, too little time. The tools that are actually delivering value in 2026 focus on better detection, triage and remediation. They reimagine existing scanners, fit into PR workflows, and measure success by whether developers actually fix things faster.
The evaluation framework is straightforward: demand transparency about models and training data, benchmark against your own codebase. AI vulnerability detection and remediation tools are maturing quickly, but the teams getting the most value are the ones treating AI as a force multiplier for their existing AppSec program, not a replacement for it.