

We are proud to introduce Beagle, the latest version of Corgea’s fine-tuned AppSec LLM. Beagle represents a groundbreaking leap in automated vulnerability management, combining precision, performance, and practicality to solve one of the most pressing challenges in application security today: effectively triaging and fixing findings from SAST scanners.
With Beagle, we’re delivering an AppSec LLM that does more than just identify potential issues—it resolves them with accuracy and balance, saving your team valuable time while enhancing your overall security posture. Beagle replaces the first version of Corgea’s AppSec LLM.
What is new with Beagle?
Beagle introduces several powerful upgrades that make it the most advanced version of our AppSec LLM yet:
Double the Training Data: Beagle has been fine-tuned with twice the amount of training data compared to its predecessor. This results in significantly higher accuracy and improved confidence in detecting and resolving vulnerabilities. It took 38 different test runs in Corgea’s test harness to product Beagle, and analyzing over 100K vulnerabilities.

Expanded Vulnerability Classes: Beagle now covers more vulnerability types, offering comprehensive security insights across a broader spectrum of issues. This ensures that no critical flaws are left undetected.
Support for 4 New Programming Languages: Beagle adds support for C, C++, PHP, and Kotlin, expanding its total language coverage to 11. Beagle now supports:

These enhancements make Beagle a truly versatile solution capable of addressing vulnerabilities in diverse codebases, from legacy systems to modern applications.
What is the underlying model and how was it trained?
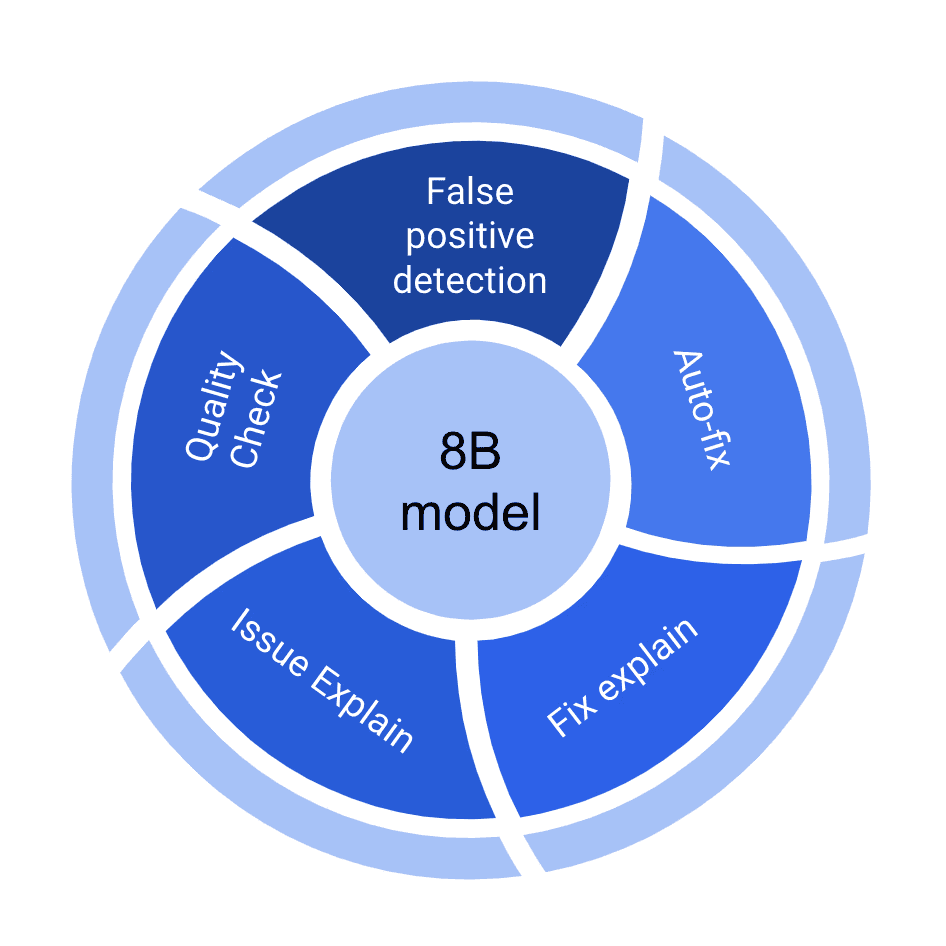
The underlying model (Llama 3.1) and our proprietary training methodology haven’t changed.The model was has multiple fine-tuned weights tailored for specific tasks, including false positive detection, automated fixes, and quality checks. This modular approach allows us to use the best of the weights for a particular task during inference. Flattening the model and merging the weights together proved to yield much worse results.
Our model is trained on a diverse dataset comprising hundreds repositories: closed-source projects we own, open-source vulnerable by design projects like Juice Shop, and other open-source codebases. Importantly, no customer data is ever used in the training process. The dataset spans multiple programming languages reflecting the diverse ecosystems our customers operate within. We also had to account for a wide range of frameworks such as Ruby-on-rails, Django, Flask, Kotlin, etc. as different frameworks handle security findings differently. For example, there are roughly 30 different ways to fix an SQL injection vulnerability as it depends on the programming language, framework and database that a particular application is using.
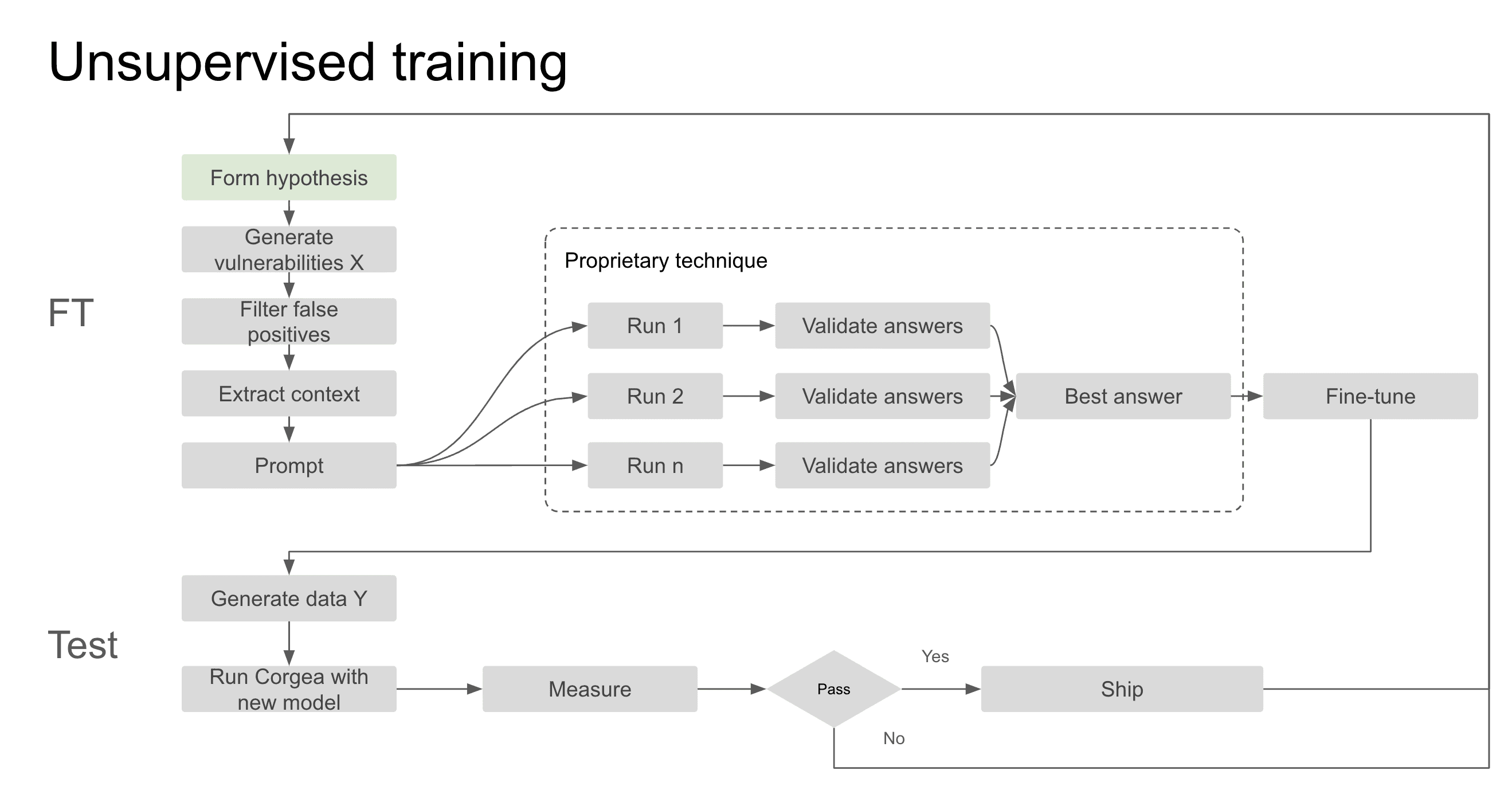
Beagle’s fine-tuning process leverages advanced unsupervised training techniques, automated false positive detection, and a proprietary test harness to rapidly scale and refine its datasets. The process begins with forming a hypothesis to address specific areas for improvement, followed by generating thousands of vulnerabilities and using Corgea’s automated false positive detection to filter out invalid findings. Relevant context, such as programming language, imports, and metadata, is extracted and fed into fixing prompts to generate solutions using frontier models. A proprietary method then validates fixes at scale, selecting the best solutions for fine-tuning in less than 24 hours without manual intervention. Once fine-tuned, the model undergoes rigorous testing in the Test Harness, where it is stress-tested on a separate dataset and benchmarked against baseline models like OpenAI and Anthropic. This ensures it meets stringent criteria for fix coverage, false positive rate, and code integrity before deployment. The entire cycle, from hypothesis to deployment, is completed in just 2-3 days, enabling Beagle to quickly adapt to feedback and evolving technology.
How Was the Assessment Conducted?
To ensure a fair and accurate comparison across all models, the evaluation of Beagle and its frontier competitors was carried out under a controlled and consistent testing environment. Here’s how the assessment was structured:
-
Standardized Processing Pipelines and Prompts:
All models were evaluated using identical processing pipelines and prompts to ensure uniformity. This eliminated any potential bias and ensured that all models were tested under the same conditions. -
Unified Pool of Vulnerabilities:
The same pool of addressable vulnerabilities was used across all evaluations. This allowed us to directly compare how each model triaged, fixed, or flagged these vulnerabilities, ensuring an apples-to-apples comparison. -
Consistent Versions of Corgea:
The same version of the Corgea platform was used for every test, maintaining a consistent infrastructure to prevent discrepancies in how vulnerabilities were processed or reported. -
Rigorous Quality Checks:
Each fix was subjected to stringent quality checks, including validation through re-scanning, syntax and semantic integrity tests, and adherence to the provided instructions. This ensured that only the highest-quality fixes were counted as validated.
By adhering to these strict evaluation criteria, we ensured that Beagle’s performance was measured accurately and fairly, providing a clear picture of its capabilities compared to other frontier models.
What Sets Beagle Apart?
Beagle’s performance reflects a meticulous balance between precision and coverage. Unlike many frontier models, Beagle doesn’t over-rely on a single metric like fix count, false positive detection, or accuracy. Instead, it delivers holistic results, ensuring high-quality fixes with minimal trade-offs. What makes this impressive is that Beagle is the smallest model out of all of the models it was benchmarked against.
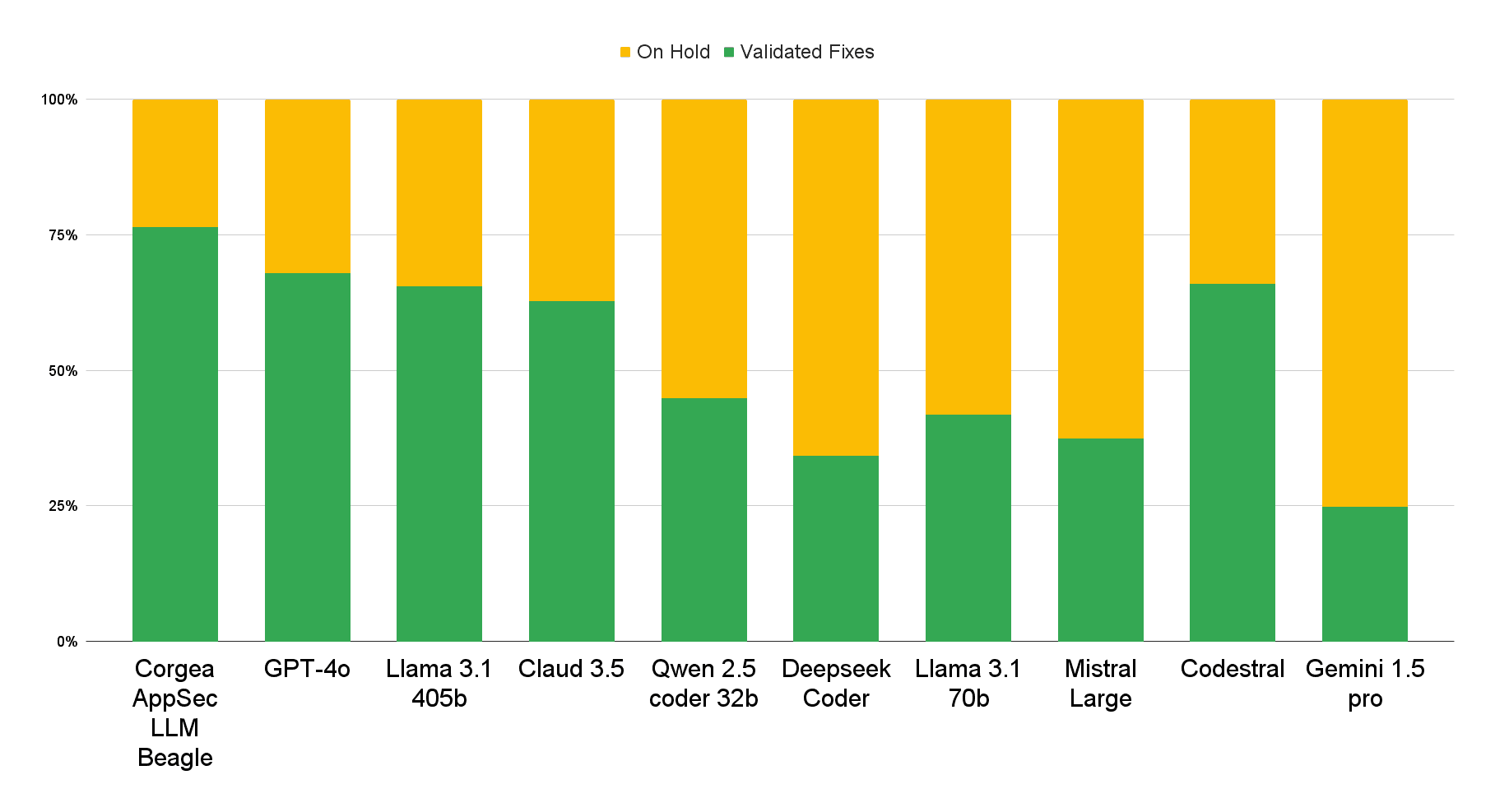
Beagle’s validated fixes stand out among frontier models. With 75% of what could be fixed (less false positives) was that passed rigorous quality checks, Beagle not only resolves vulnerabilities but does so without breaking syntax, semantics, or introducing new issues. This balance ensures your codebase remains secure and stable, no matter the scale of findings. Vulnerabilities that were marked “On Hold” are vulnerabilities that could not be fixed by Corgea due to complexity or not producing an appropriate fix. These would not be shown to a user to make sure fix quality is high. Beagle is the lowest in this metric.
A Balanced Approach to False Positive Detection
False positive detection is critical but nuanced. Over-detecting false positives can be just as harmful as missing them, as it may lead to overlooking legitimate vulnerabilities. Beagle excels at striking the right balance, avoiding over-detection while maintaining high confidence in its classifications.
Take for example Codestral, while someone might think that it’s doing a great job here, it’s actually over-reporting.
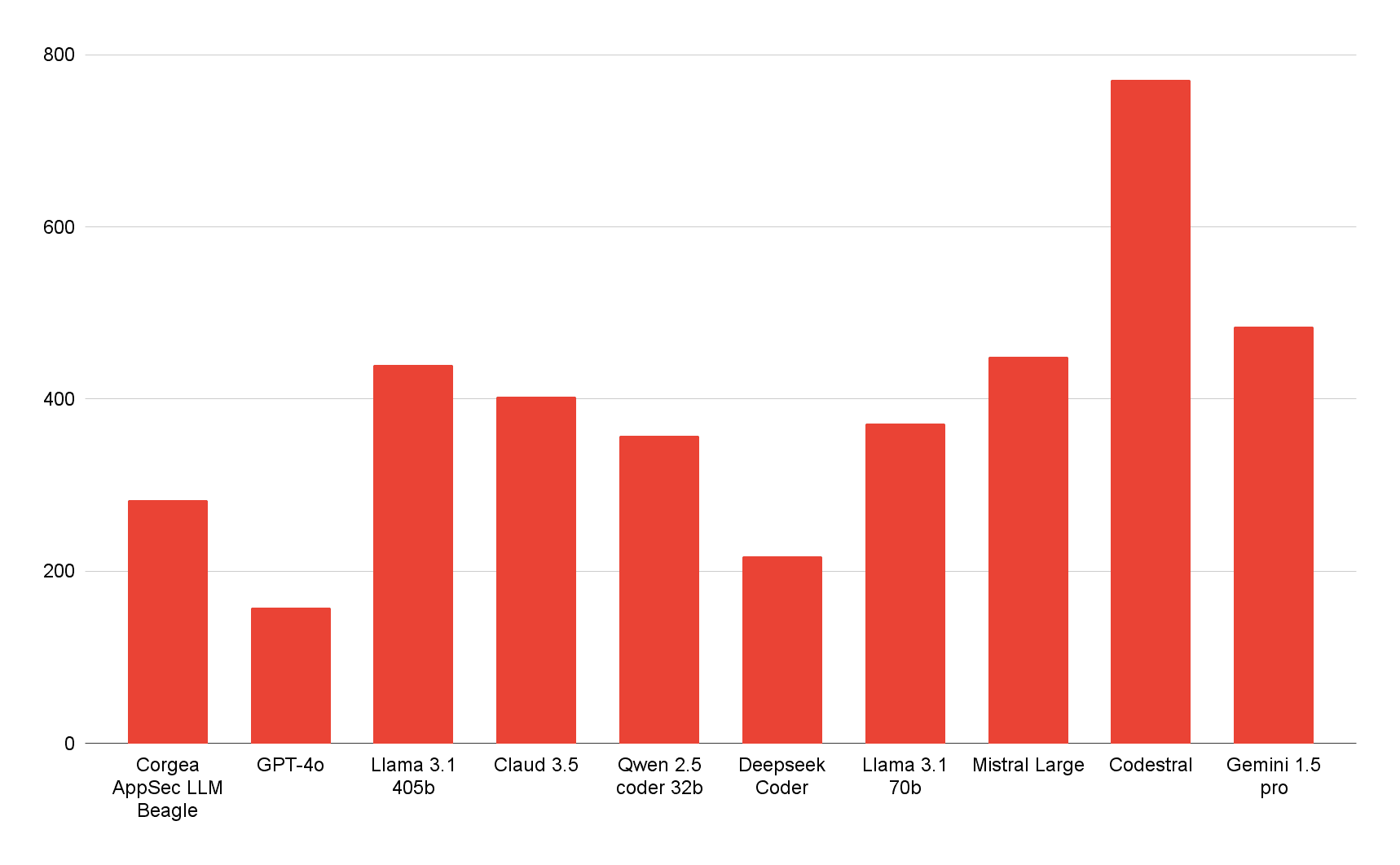
The data demonstrates that Beagle minimizes false positive noise, allowing security teams to focus on the most relevant and impactful findings. This capability ensures teams aren’t overwhelmed by unnecessary alerts or distracted from addressing real vulnerabilities.
Coverage and Accuracy: The Perfect Harmony
Fixing vulnerabilities isn’t just about accuracy; it’s about addressing enough of them to make a meaningful impact. Some models prioritize accuracy but fail to scale across a large number of issues, making them impractical for real-world use cases. Take for example Llama 3.1 405b. The model is 50x larger but inches fix accuracy by a couple of percentage points, but has 38% less fixes due to it over detecting false positives that aren’t valid. Additionally, hosting a 405b model is prohibitively expensive as it requires at least 240GB of VRAM. Beagle, on the other hand, excels both in coverage and quality and can be on a single A10 24GB GPU.
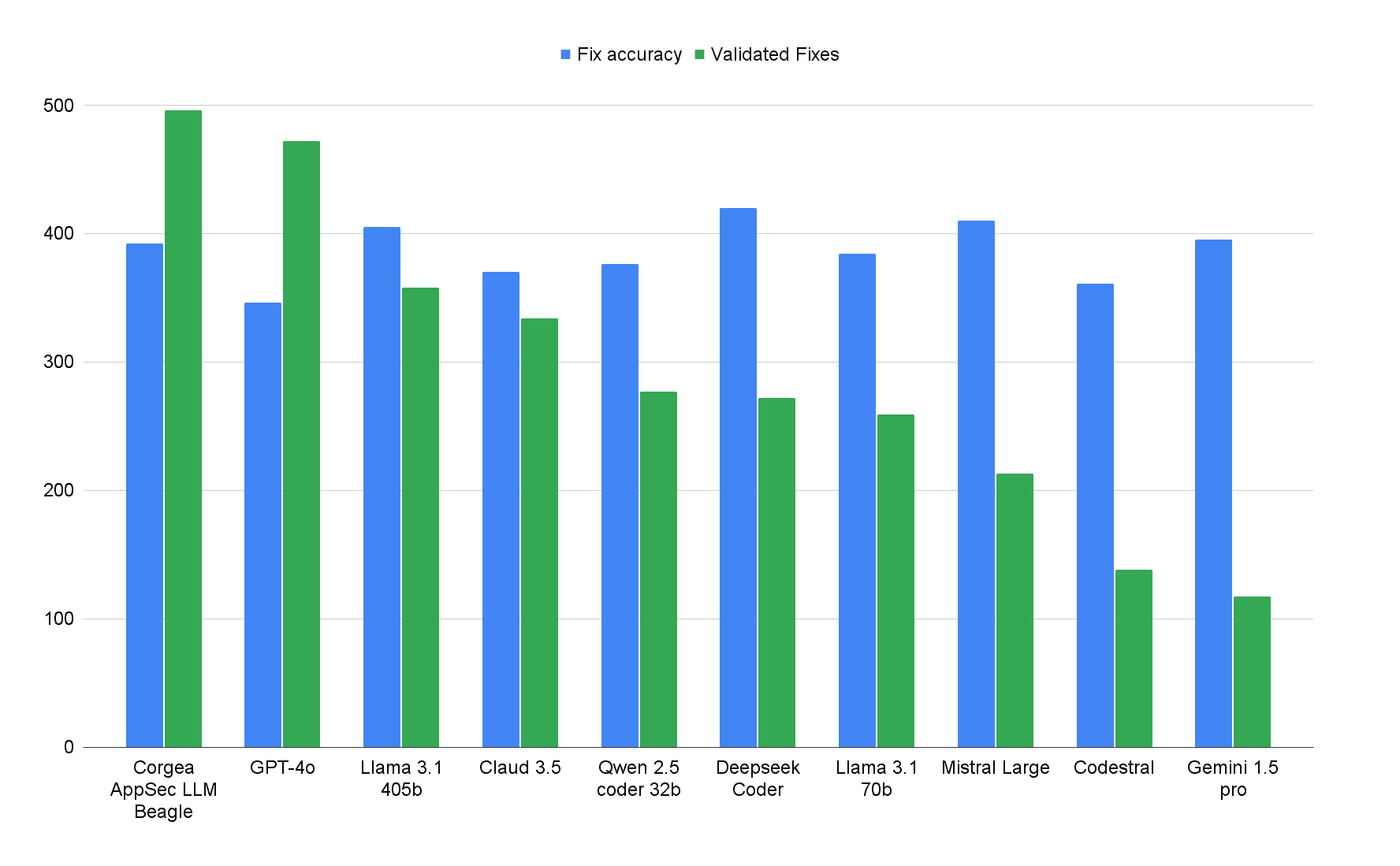
As shown in the comparison, Beagle delivers fixes at scale while maintaining exceptional accuracy. This ensures vulnerabilities are comprehensively addressed without compromising the quality of each fix.
Beagle’s Balanced Performance Across Metrics
What truly sets Beagle apart is its holistic approach. It doesn’t just excel in one area—it achieves balance across multiple key metrics, including validated fixes, false positive detection, and on-hold cases. This approach ensures that every output is actionable and reliable.
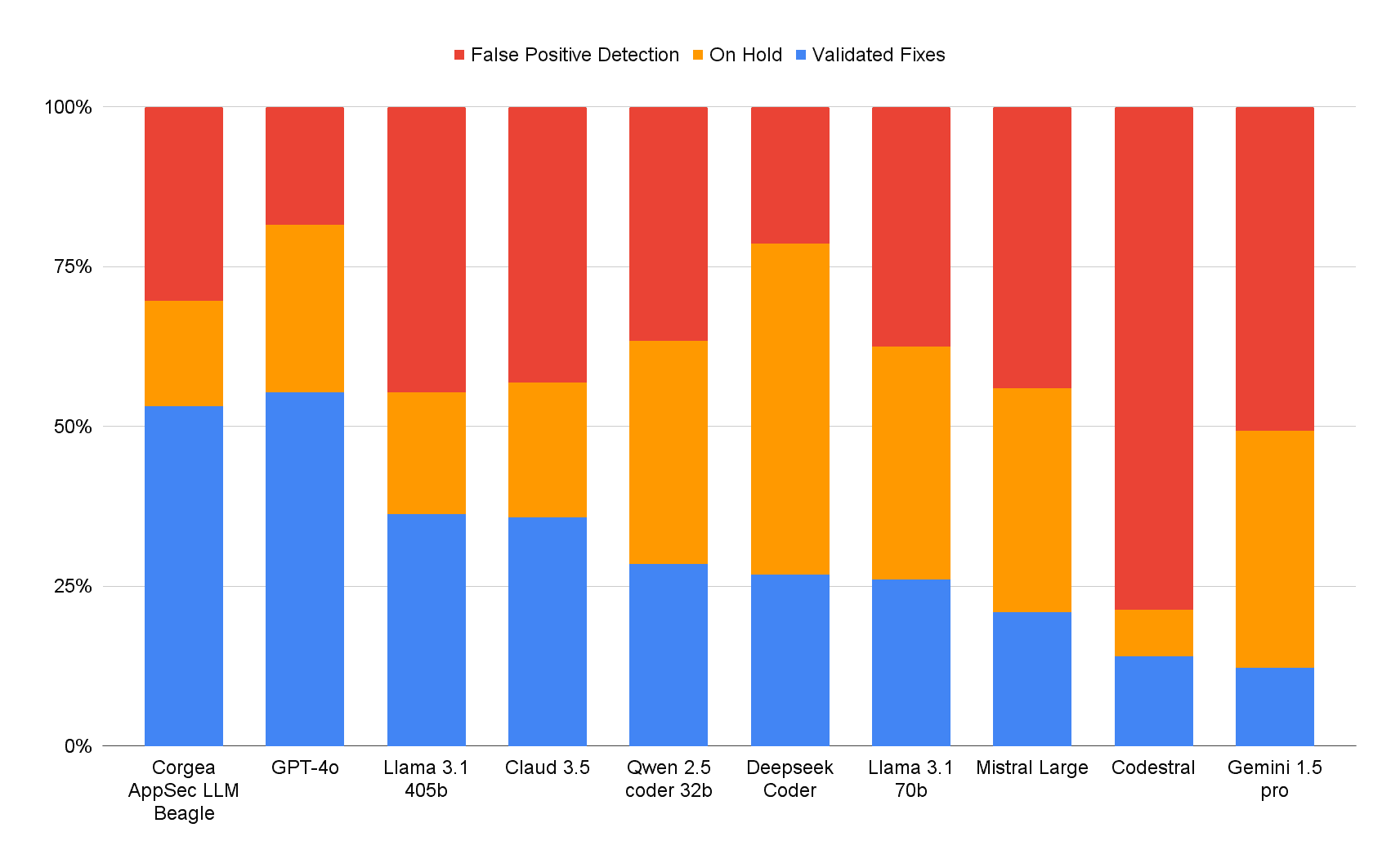
Beagle’s balanced distribution of validated fixes, false positive detection, and on-hold cases makes it the most dependable AppSec LLM for real-world environments. It delivers the highest number of validated fixes with the least amount of “on-hold” findings, reflecting its confidence and capability to tackle complex vulnerabilities.
Why Beagle Matters for Your Security Team
Beagle is more than just a technical innovation—it’s a productivity accelerator for security teams. By automating triaging and fixing vulnerabilities at scale, it reduces noise, improves efficiency, and lets your team focus on the issues that matter most.
Key Benefits of Beagle:
-
Reduced Noise: Minimized false positives and on-hold cases mean less wasted time.
-
High Fix Quality: Validated fixes that maintain syntax, semantics, and overall code integrity.
-
Comprehensive Coverage: A perfect balance between fix accuracy and count for broad and reliable vulnerability resolution.
Transform Your Application Security with Beagle
Beagle is a testament to Corgea’s commitment to pushing the boundaries of what’s possible with AI in application security. By combining cutting-edge technology with practical results, Beagle is poised to redefine how organizations approach AppSec.
Ready to experience the next generation of automated application security? Book a demo with us.