

I’m Ahmad, the founder of Corgea. We’re building an AI AppSec engineer that helps developers automatically triage and fix insecure code. We help reduce 30% of SAST findings with our false positive detection and accelerate remediation by ~80%. To do this for large enterprises we had to fine-tune a model that we can deploy that is secure and private.
Why Did We Fine-Tune Our Own LLM?
Enterprises, especially those in regulated industries, have stringent requirements for data residency, privacy, and security. These organizations often demand private-cloud deployments and need to avoid reliance on third-party LLMs that could pose data exposure risks. Our fine-tuned LLM addresses these concerns by offering complete data isolation and avoiding the need for customers to sign Business Associate Agreements (BAAs) for HIPAA compliance. Additionally, this approach allows for a low-cost deployment model while outperforming even larger models like OpenAI’s in relevant benchmarks.
Model Structure: The Core of Our Solution
At the heart of our solution is Llama 3.1 8B which is an 8 billion parameter core model. We benchmarked all the popular small models against each other including Mistral, Mixtral, Codestral mamba, and Deepseek coder. We chose Llama 3.1 8B due to it’s size, ease of fine-tuning, measurable performance in key areas we need, and newness.
The model was has multiple fine-tuned weights tailored for specific tasks, including false positive detection, automated fixes, and quality checks. This modular approach allows us to use the best of the weights for a particular task during inference. Flattening the model and merging the weights together proved to yield much worse results.
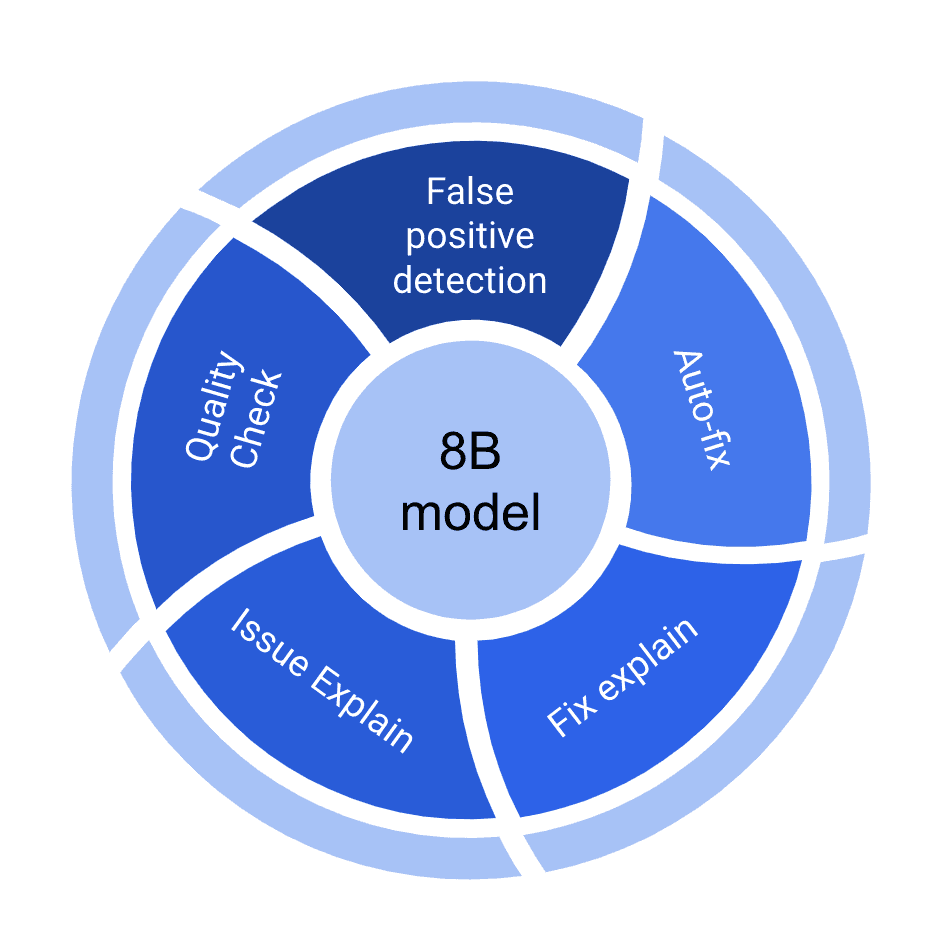
You might be wondering, do you deploy your model 5 times? No, we deploy the core model, and route the request to the active weight we need. For example, if we’re fixing, then the model will load the active fixing weights, and then switch to another task when needed. This allows us to deploy Corgea on a single A10 24GB GPU and be performant with switching latency being ~10ms.
Why is all of this important? Saving customers from having to host a big model in their private cloud. Larger models that require more GPU RAM and stronger GPUs are expensive. This solution is very cost effective.
The Fine-Tuning Process: From Hypothesis to Deployment
Fine-tuning seemed like it could be a very big task. As they say “garbage in, garbage out” so it was critical for us to pick the best fixes across a diverse set of programming languages, frameworks and vulnerabilities with the least amount of false positives. As a startup, we do not have an army of people to label issues as false positives, and pick the best fixes to feed into a model for training. We had to get innovative.
What is Our Dataset?
Our model is trained on a diverse dataset comprising hundreds repositories: closed-source projects we own, open-source vulnerable by design projects like Juice Shop, and other open-source codebases. Importantly, no customer data is ever used in the training process. The dataset spans multiple programming languages, including Python, JavaScript, TypeScript, Java, Go, Ruby, and C#, reflecting the diverse ecosystems our customers operate within. We also had to account for a wide range of frameworks such as Ruby-on-rails, Django, Flask, Kotlin, etc. as different frameworks handle security findings differently. For example, there are roughly 30 different ways to fix an SQL injection vulnerability as it depends on the programming language, framework and database that a particular application is using.
How Does Training Work?
Using unsupervised training techniques, our false positive detection feature and our test harness, we were able to build a fine-tuning system that allowed us to scale data set selection.
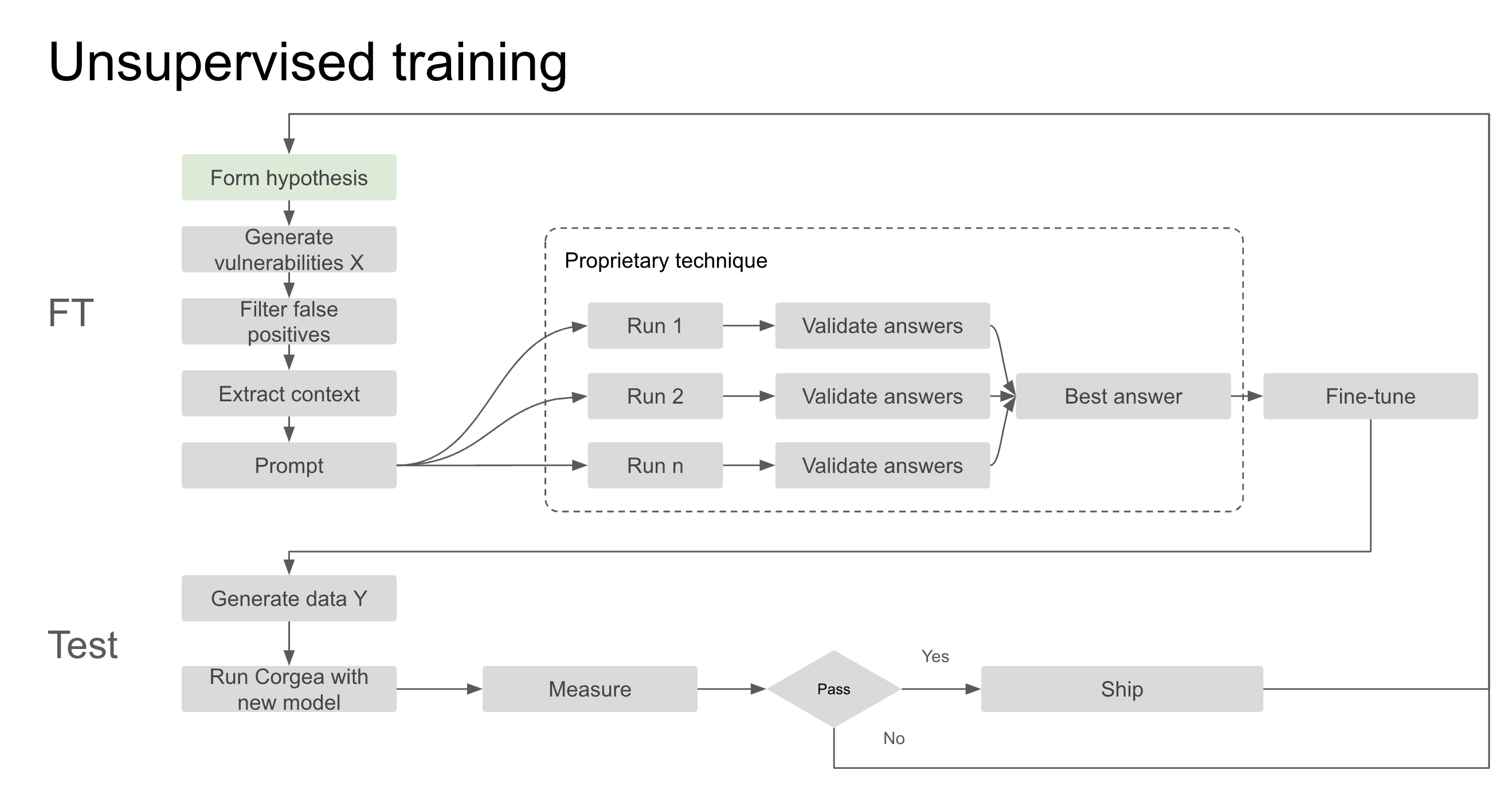
The fine-tuning process begins with forming a hypothesis based on a specific area we need to build or improve. We generate thousands of vulnerabilities from the data set above. We then use our automated false positives feature in Corgea to weed out bad findings. This is critical to make sure the model doesn’t get trained on fixes for code that was never vulnerable.
We then automatically extract the relevant context such as detecting which language we’re working with, what imports are being called, the functional block of code that’s vulnerable, the vulnerability and other meta data. This is then fed into our fixing prompt to generate the fixes with frontier models.
We developed a proprietary technique that involves running multiple fix and validation cycles against frontier models to ensure the best possible answers are selected before final fine-tuning. What would’ve taken us weeks of data labeling now can be accomplished in less than 24 hours with no human intervention. This now becomes our training data, which is then fed into our fine-tuning process.
Once fine-tuning is complete, the model undergoes extensive testing using our Test Harness. In Test Harness, we stress test this new model on a different dataset to validate the model’s performance, and compare it to a baseline against other frontier models such as OpenAI and Anthropic. Only when it meets our stringent pass criteria do we deploy it. Things we check for are fix coverage, false positive rate, syntax issues, semantic issues, etc. The entire process, from hypothesis to deployment, can be completed in just 2-3 days, allowing us to quickly adapt to feedback and new emerging tech.
The Results: Performance and Efficiency
The benchmarks speak for themselves: Corgea’s Security LLM outperforms OpenAI’s models by 7% while being ~90% smaller. Almost every vulnerability class became better.
For example XSS and code injection had ~30% and 77% less issues across all languages respectively. We witnesses certain classes for vulnerabilities got significantly better because of this fine-tuning. For example, path traversal (CWE-22) has 2.85x more valid fixes, and insufficient regular expression complexity (CWE-1333) got 4x more valid fixes. Fix accuracy within certain languages became better. For example Javascript fixes were 12% more valid.
More tactically we also saw the model become better at even simple things like not changing whitespaces unnecessarily, modifying unrelated code, over-fixing, and hallucinating. Smaller models are also typically less obedient to instructions, and would miss certain instructions we’d feed it such as following our output format. Fine-tuning really helped reduce these issues.
These performance gains are critical for enterprises that need highly accurate results without the overhead of massive computational resources. Moreover, our model’s smaller size means it can be deployed more cost-effectively, further reducing the total cost of ownership. Additionally the model performs on-par with OpenAI for false positive detection, explaining vulnerabilities and generating a summary of changes for the diff.
Conclusion
Corgea’s fine-tuned LLM is designed to meet the unique needs of enterprises by providing a robust, privacy-focused solution that enhances application security. By leveraging our fine-tuning process and a carefully curated dataset, we offer a model that delivers exceptional performance and cost efficiency. This ensures that enterprises can confidently deploy our solution within their private clouds, knowing that their data remains secure while benefiting from state-of-the-art vulnerability management.
This fine-tuning initiative is not just about enhancing a model; it’s about addressing the specific challenges enterprises face in application security. With Corgea, enterprises can expect faster, more accurate vulnerability management, all while maintaining complete control over their data.