

One of the most famous laws in open source is Linus’s Law: given enough eyeballs, all bugs are shallow.
The idea was simple: if enough people inspect, use, and contribute to software, bugs eventually surface. For decades, that model gave defenders a kind of economic advantage. Finding serious vulnerabilities required scarce human expertise, patience, and time.
That advantage is disappearing. LLMs have changed the model to something more unsettling: Given enough inference, all bugs are shallow.
A single attacker can now compress weeks of research into hours. I have personally found multiple high-severity issues in under 15 minutes, including one in Axios, a JavaScript package downloaded nearly 100 million times per week.
That is the security arms race Mythos represents. It shows what happens when frontier models are pointed at real software with enough inference behind them. But it also raises the question every security buyer should care about: If more inference finds more bugs, who pays for the inference?
The Benchmark
We ran a simple benchmark to test this question.
We took a deliberately vulnerable multi-language application suite covering Python, JavaScript, Java, Terraform, Kubernetes manifests, and other common application surfaces.
Then we scanned it three ways:
- Claude Opus 4.6 using
/security-reviewwith a 1-million-token context window - Corgea v1 using GPT-4.1
- Corgea v2 using GPT-5.4
Before scanning, we removed all canary comments. Then we manually verified every result against the actual source code.
The benchmark included 49 ground-truth vulnerabilities across SQL injection, XSS, SSRF, command injection, CSRF, path traversal, unsafe deserialization, access control, information exposure, and more.
We wanted to show how a small and simple app showed key differences between them.
The results:
| Claude (Opus 4.6) | Corgea v1 (GPT-4.1) | Corgea v2 (GPT-5.4) | |
|---|---|---|---|
| Reasoning | Yes | No | No |
| Detected | 30 | 36 | 34 |
| Missed | 19 | 13 | 15 |
| False Positives | 1 | 3 | 0 |
| Precision | 96.80% | 93% | 100% |
| Recall | 61.20% | 73.50% | 69.40% |
| F1 Score | 75.00% | 82.10% | 81.90% |
| Cost in per million | $5.00 | $2.00 | $2.50 |
| Cost out per million | $25.00 | $8.00 | $15.00 |
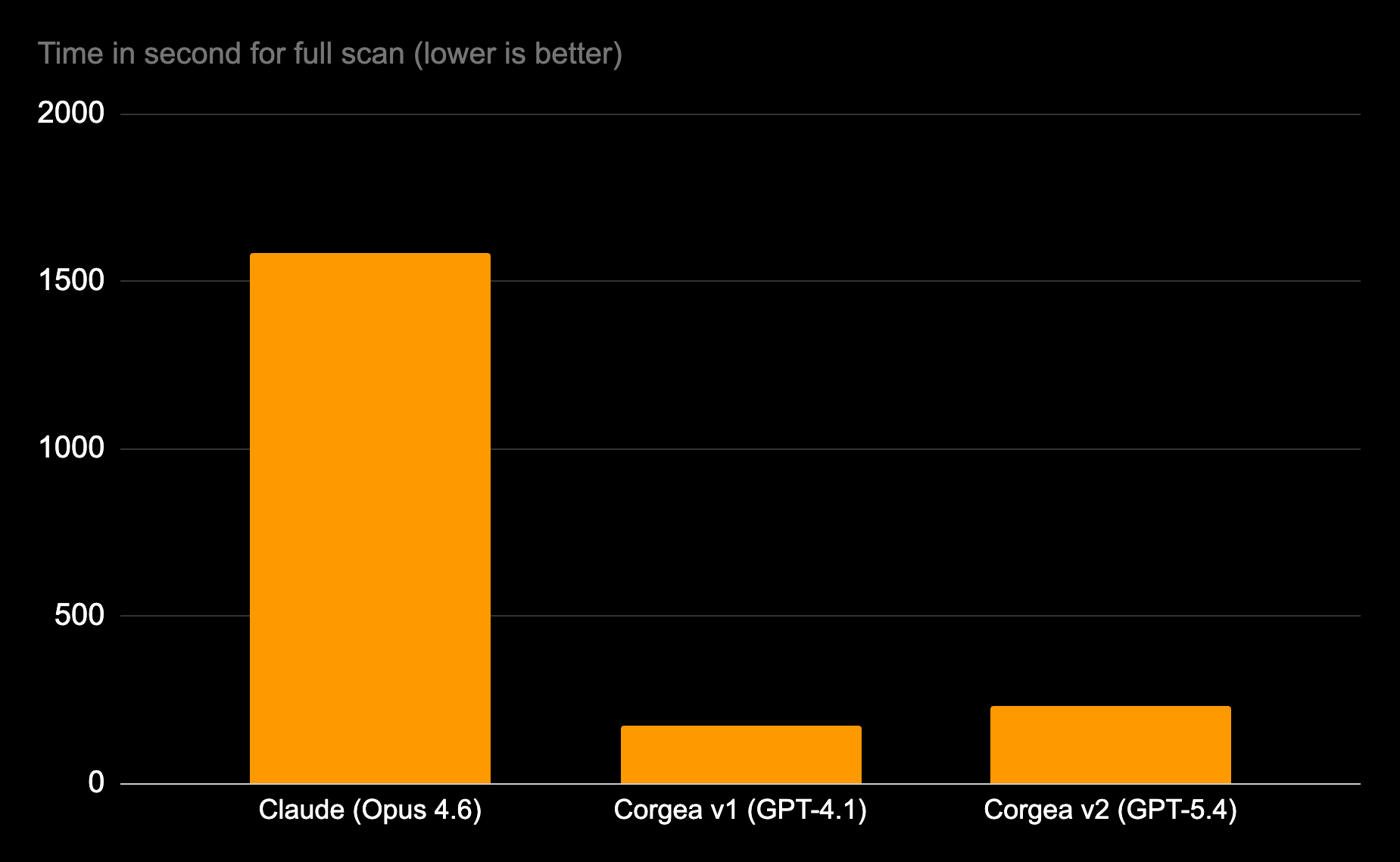
| Scan speed in seconds | 1,586 seconds | 171 seconds | 232 seconds |
While Opus 4.6 has premium pricing above 200K tokens at $10/M input and $37.50/M output, we reflected it as $5/M input and $15/M output to be fair.
The result is not that models do not matter. They clearly do. GPT-5.4 eliminated every false positive produced by GPT-4.1. It improved CWE classification. It found vulnerabilities no other scanner found, including unbounded request body handling, stack-trace leakage, and SQL error exposure.
But the result also shows something important:
Model capability alone is not enough.
Claude used a frontier model, reasoning, and a massive context window. It still had the lowest recall, took 6–9x longer to run, and missed entire vulnerability classes. The GPT-4.1 to GPT-5.4 comparison is the most revealing data point in the benchmark, because it shows what purpose-built architecture does with better base models.
GPT-5.4 eliminated every false positive that GPT-4.1 produced. It corrected CWE misclassifications, applying CWE-639 (authorization bypass through user-controlled key) where GPT-4.1 had used the less precise CWE-306 (missing authentication). It discovered three vulnerabilities—an unbounded request body (CWE-400), an error handler leaking full stack traces (CWE-209), and SQL error messages exposed to end users (CWE-209)—that no scanner in the benchmark detected, including Claude on a million-token context window. And it picked up two findings that had previously been exclusive to Claude: a path traversal via unsanitized filename and plaintext credit card numbers stored in source.
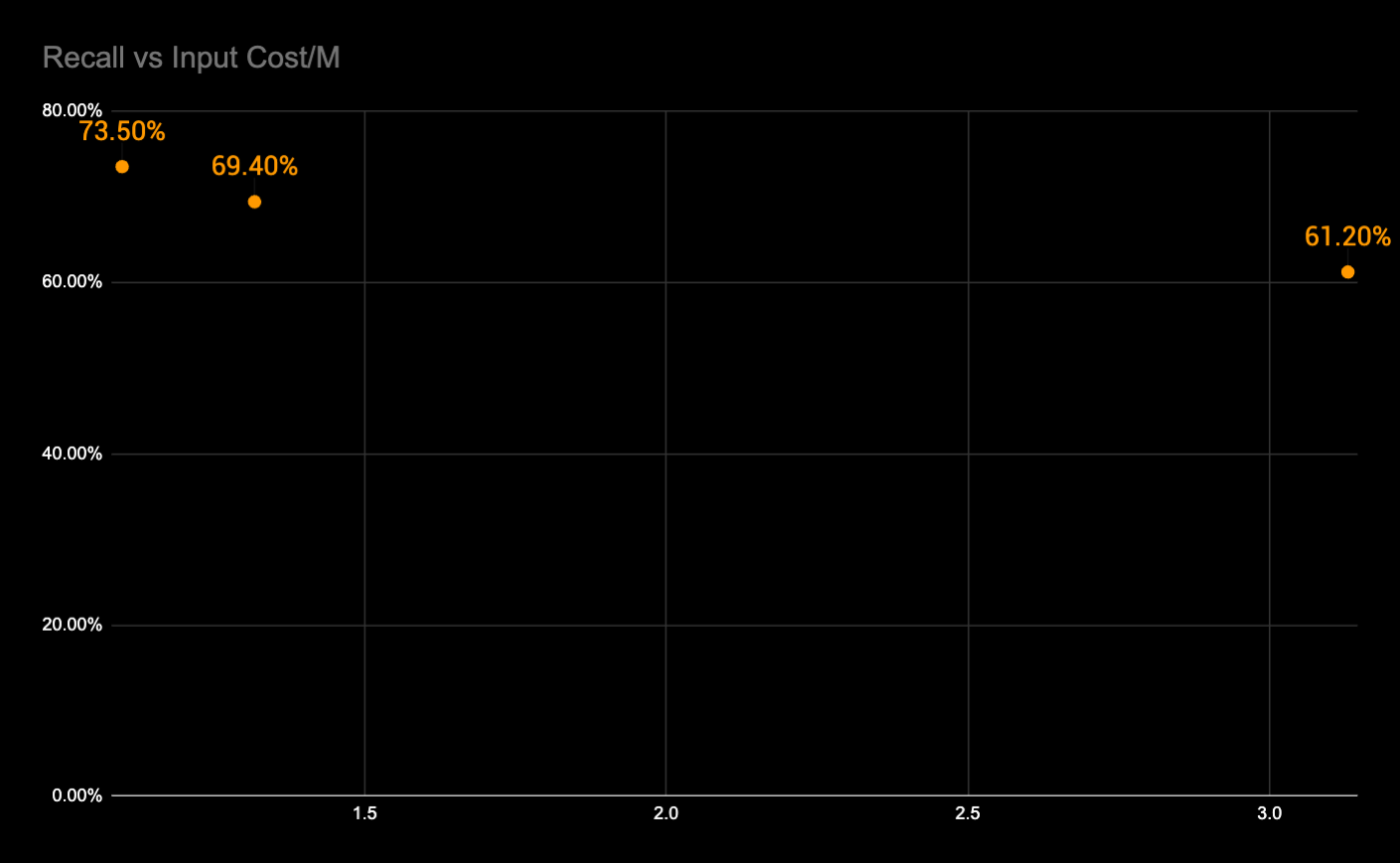
The F1 scores tell the aggregate story: 81.2% on GPT-4.1, 81.0% on GPT-5.4, 75.6% on Claude Opus 4.6. A model at $2.50 per million input tokens matches or exceeds the performance of a frontier model at $5.00 per million input tokens.
Corgea ran faster, cheaper, non-reasoning model, and with better aggregate performance because the model was not operating alone. It was operating inside a purpose-built security architecture.
Models find possibilities. Architecture turns them into security outcomes.
The right debate is not “model versus architecture.”
Models and architecture compound each other. A stronger model helps, but only if the system gives it the right context, asks the right question, verifies the right evidence, and turns the result into something that both developers and security can trust.
In AppSec, architecture determines whether model intelligence becomes:
- a real vulnerability,
- a false positive,
- a missed issue,
- an accepted fix,
- or just an expensive token bill.
That distinction matters because secure code analysis is not a single prompt.
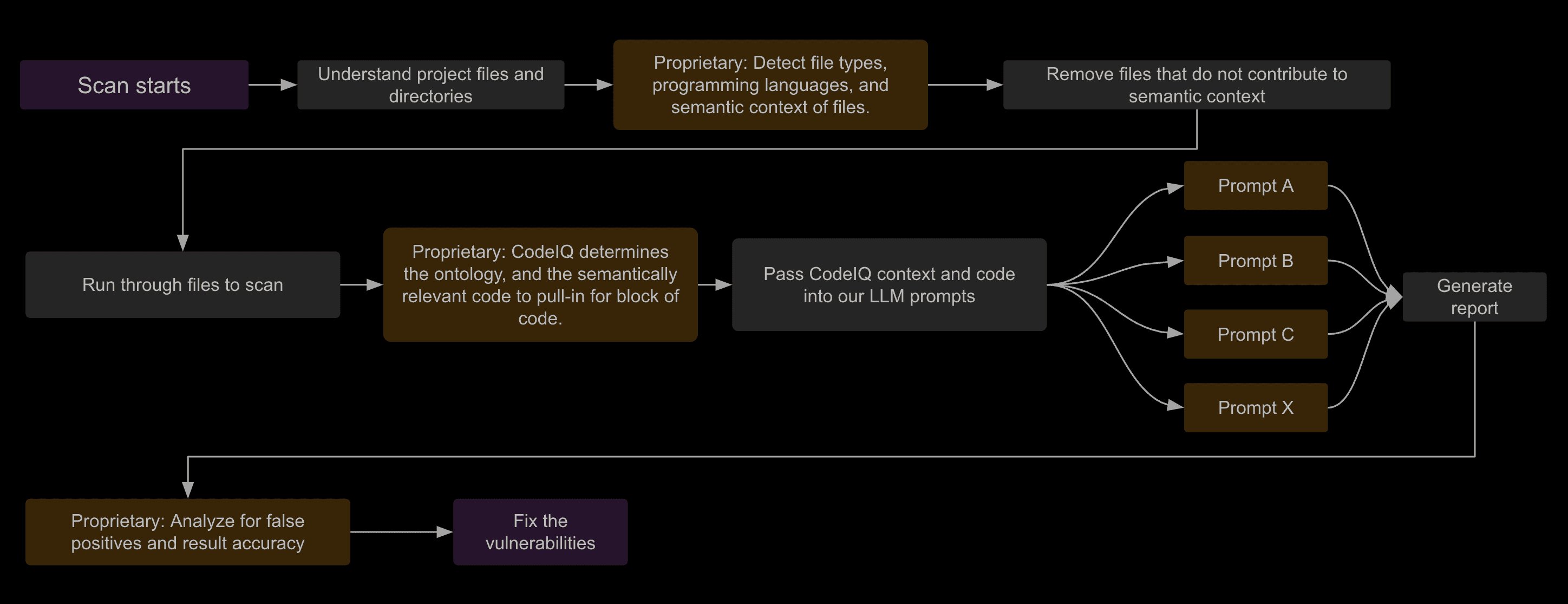
At a high level, Corgea’s scanner does four things.
- It builds a semantic map of the project: languages, frameworks, routes, controllers, middleware, auth boundaries, dependency files, configs, IaC, and containers.
- It extracts vulnerability-specific context. SQL injection needs query construction and data-flow context. Auth bypass needs route, middleware, decorator, and identity propagation context. SSRF needs request construction, sinks, and allowlist behavior. XSS needs template, escaping, and render-path context.
- It routes analysis through vulnerability-specific detection passes. Different classes require different prompts, evidence thresholds, and validation logic.
- It post-processes findings for evidence, deduplication, CWE accuracy, false-positive suppression, and fixability.
That is why “just use a bigger model” is not the same thing as production AppSec.
The Economics of Security
Traditional SAST tools are fast and cheap, but they miss too much. Depending on the benchmark, many miss in-between 47% and 80% of the vulnerabilities. LLMs help break through that ceiling. They understand code more semantically. They can reason about framework behavior, data flow, authentication assumptions, and intent. But raw model capability does not automatically become production-grade AppSec. Check out our whitepaper on the topic.
For buyers, this is why evaluating AI-native SAST tools requires measuring precision, recall, cost, scan speed, false positives, and fix quality together.
A scanner that finds slightly more bugs but costs 10x more to run may be worse for most AppSec teams than a system with slightly lower recall, much higher precision, faster scans, and better recall per dollar.
This is where many frontier-model wrappers fall into what I call the subsidizing zone. In the subsidizing zone, the customer is not really buying security. They are paying for inference. Every extra scan, repeated pass, long-context prompt, reasoning trace, and agentic scaffold pushes margin toward whoever sells the tokens.
That may be acceptable for research. It is much harder to justify as the operating model for production AppSec.
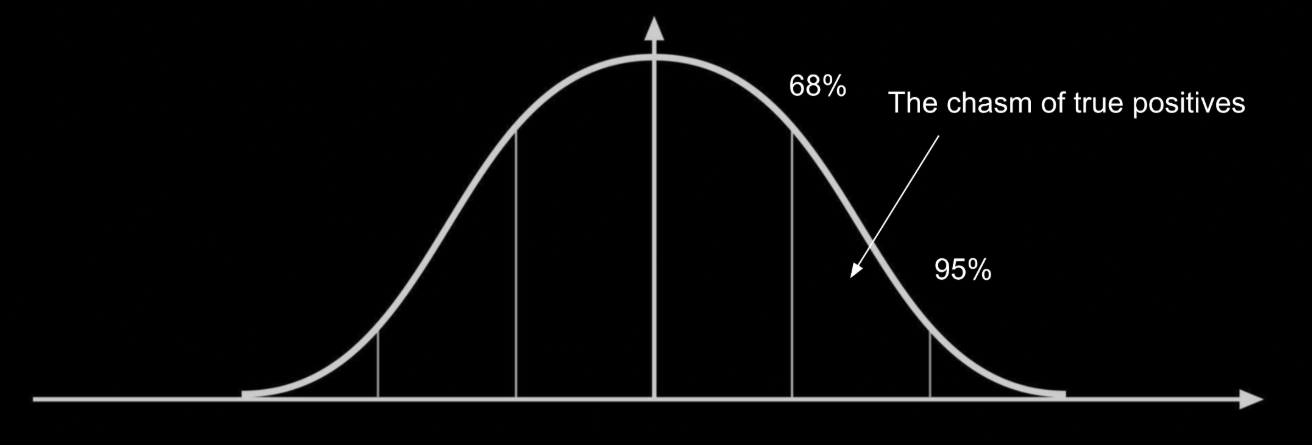
The industry needs to get to 2σ (95% of potential vulnerabilities) but do it affordably. Getting to 95% becomes exponentially more difficult because of a variety of reasons such as detecting more subtle vulnerabilities that need detection, context decay, codebase implementations that introduce complexity. Model improvements will definitely help here, but that’s not the only answer.
How do we get there? We see two options:
- Throw much more inference with larger models and have n-passes scan multiple times which is immensely expensive and slow. This is what Anthropic did: “This was the most critical vulnerability we discovered in OpenBSD with Mythos Preview after a thousand runs through our scaffold. Across a thousand runs through our scaffold, the total cost was under $20,000 and found several dozen more findings.”
- Deepen architectural investment in our scanning pipelines rather than just relying on larger models.
Option 2 seems the most promising but to do so not with just current surface level implementation. AST-aware context extraction, multi-pass scanning, and prompt routing are not novel in the abstract. Many teams can claim some version of them.
The hard part is not saying “we use ASTs.” The hard part is building the production judgment layer around them.
That means knowing:
- which context matters for each vulnerability class,
- which files are security-relevant and which are noise,
- which framework idioms change exploitability,
- which findings developers actually accept,
- which evidence thresholds prevent false positives,
- which remediation patterns survive tests,
- and which model behaviors are stable enough for production use.
That system compounds with every scan, every verified finding, every rejected false positive, and every merged fix. So the question is not whether someone can copy the words “context extraction” or “multi-pass scanning.” They can. The question is whether they can reproduce the judgment layer built from real-world code, real customer workflows, and manually verified security outcomes.
That is the difference between an integration pattern and a production-grade system.
Now, Mythos
As a thought experiment, let’s assume Mythos has an 80% Recall rate (7% more than our best run), is it worth it if it’s 14x more expensive than current benchmarks? The answer is no, and you’re likely to find these during pentesting, DAST, etc.
This is also evident in Anthropic subsidizing $100M to its selected customers to run it. The economics don’t pan out as that’ll blow away security budgets.
Additionally it seems that the false positive rate is pretty significant according to Daniel Stenberg, maintainer for curl:
“Five issues felt like nothing as we had expected an extensive list. Once my curl security team fellows and I had poked on this short list for a number of hours and dug into the details, we had trimmed the list down and were left with one confirmed vulnerability. The other four were three false positives (they highlighted shortcomings that are documented in API documentation) and the fourth we deemed ‘just a bug’.”
The marker, not the future
Mythos will be remembered like the first commercial firewall or the first cloud WAF—a moment of category legitimization, not a final form.
The AppSec market is expanding, not compressing. AI-generated code is the majority of new commits at many organizations. Vulnerabilities are growing faster than the code itself. Time-to-exploit has gone negative. The supply chain has industrialized. That’s not consolidation, it’s structural deficit. Mythos didn’t make AppSec smaller. It made insecurity bigger.
Scanner architecture can dominate model choice when cost, speed, determinism, and triage time are included. A purpose-built scanner on GPT-5.4 achieves 100% precision and a higher F1 score than a raw frontier model at 2–3x the price. The architecture matters more than the model. The recall-per-dollar matters more than the recall.
Given enough inference, all bugs are shallow. The question is who’s paying for the inference, and for how long that math holds.