

We benchmarked Corgea and Aikido against latiotech/insecure-kubernetes-deployments, a deliberately vulnerable repository with application, API, JavaScript, Kubernetes, and configuration weaknesses.
The result was not close. Aikido produced a smaller, cleaner set of findings. Corgea found the vulnerabilities.
Out of 47 source-confirmed issues, Corgea found 42. Aikido found 13. Corgea reached 89.36% recall and 85.71% F1. Aikido reached 27.66% recall and 41.94% F1.
Corgea found 42 of 47; Aikido found 13
Same deliberately vulnerable repository, same review process, 47 source-confirmed issues. Aikido was slightly cleaner per reported finding, but Corgea found far more of the vulnerabilities that needed remediation.
3.23x Aikido's recall, 2.04x its F1, and 29 more confirmed vulnerabilities found.
| Tool | Findings reviewed | TP | FP | FN | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| Corgea | 51 | 42 | 9 | 5 | 82.35% | 89.36% | 85.71% |
| Aikido | 15 | 13 | 2 | 34 | 86.67% | 27.66% | 41.94% |
Scoring set: 47 source-confirmed issues reviewed on 2026-07-02. Precision = TP / (TP + FP), recall = TP / (TP + FN), F1 = harmonic mean of precision and recall.
Aikido was slightly cleaner; Corgea was far more complete
Bubble position shows precision and recall. Bubble size shows confirmed true positives. The upper-right corner is the goal: high confidence and broad vulnerability discovery.
Precision and recall use the same July 2, 2026 scoring set of 47 source-confirmed issues.
The important distinction is simple: Aikido had slightly higher precision, but it missed 34 confirmed vulnerabilities. In a real remediation program, a missed vulnerability does not enter the backlog, does not get assigned, and does not get fixed. The limitation is Aikido’s OpenGrep-based, traditional static analysis layer: useful for known patterns and source-to-sink rules, but weaker when the scanner needs broader repository context, framework understanding, and reasoning across custom application logic.
The benchmark setup
We compared Corgea and Aikido scan results from July 2, 2026.
Each finding was reviewed against source and classified as:
| Classification | Meaning |
|---|---|
| True positive | The reported vulnerability, or a directly equivalent weakness, is present in source. |
| False positive | The report is unsupported, materially misclassified, duplicated under the wrong class, or points to non-vulnerable code. |
| False negative | A source-confirmed benchmark issue the tool did not report. |
The scoring set contained 47 source-confirmed application and configuration security issues. Precision, recall, and F1 used standard definitions.
Because this was James Berthoty’s Latio benchmark repository, the test corpus was intentionally noisy and broad. The repo describes its purpose plainly:
“Test every type of configuration scanner against a single repo that’s comically insecure with documented issues.”
That is exactly what makes it useful for a head-to-head comparison: the benchmark is not optimized for one narrow vulnerability class or one scanner’s preferred path.
Why recall decided the benchmark
Security teams do care about false positives. A noisy scanner loses developer trust. But in this benchmark, the precision spread was small: Aikido scored 86.67% precision and Corgea scored 82.35%.
The recall spread was enormous. Corgea found 42 confirmed issues. Aikido found 13. That is the operational story.
A small precision edge did not make up for 34 misses
Aikido's output had fewer false positives, but its SAST scan left most confirmed issues behind. For remediation planning, missed vulnerabilities are the larger operational risk.
Examples Corgea found that were absent from the Aikido results:
- Missing authorization on data-modifying FastAPI routes
- SSRF in a URL fetch endpoint
- Open redirect through an unvalidated next parameter
- Lodash template code injection
- Prototype pollution risk around JSON5 parsing
- Hardcoded AWS credentials in Kubernetes deployment templates
- Hardcoded API tokens in test code
Each stacked bar totals 47 source-confirmed issues. Found percentages: Corgea 89%, Aikido 28%.
Aikido’s cleaner output meant fewer incorrect reports to triage. But the price of that clean output was 34 missed confirmed vulnerabilities, including missing authorization, SSRF, open redirect, template code injection, prototype pollution, and hardcoded credentials.
Why OpenGrep-style SAST was not enough
OpenGrep is a useful static analysis engine, and traditional SAST still matters. It is fast, rule-driven, and good at catching recognizable insecure patterns. That explains why Aikido found real issues such as SQL injection, command injection, and XXE.
The limitation is relying on that style of analysis as the primary layer for custom-code security. OpenGrep-style rule and pattern engines can struggle when the vulnerability depends on application context, framework conventions, authorization boundaries, or multi-file reasoning. Those are exactly the categories where Aikido missed coverage in this benchmark.
Corgea’s approach is different: Corgea AI SAST combines static analysis with code context, reachability, and AI-native reasoning. The architecture behind this is covered in the BLAST AI-powered SAST whitepaper, and the broader shift from rules to AI-native analysis is explained in The Three Waves of SAST. If you are building an evaluation rubric, pair this benchmark with how to evaluate AI-native SAST tools and how to reduce false positives in SAST.
Corgea also led Latio’s auto-fix benchmark
Detection depth matters most when the scanner can also help developers fix what it finds. In a separate Latio Tech auto-fix benchmark, James Berthoty scored vendors on final score: coverage x quality. Corgea ranked #1 with a score of 719. Aikido ranked #6 with 336.
Latio ranked Corgea #1 and Aikido #6 for SAST auto-fixing
James Berthoty at Latio Tech scored 7 auto-fix vendors by final score: Coverage x Quality. Corgea led with 719; Aikido ranked #6 with 336.
"pretty mindblowing in a lot of respects"
Latio highlighted Corgea for a robust LLM-based SAST scanner, simple developer experience, strong explanations, contextual policy work, and an agentic prompting approach across fixes, validation, and code context.
"fix coverage was low"
Latio noted that Aikido was rapidly improving and prioritized accuracy by rolling out fixes rule by rule, but its lower coverage limited the final score.
Source: Actually Useful Product Guide by James Berthoty at Latio Tech. Full 7-vendor benchmark shown; non-Corgea/non-Aikido rows are muted to keep the comparison focused. Read Corgea's summary of the report here.
Where both tools agreed
Both tools found important vulnerabilities in the benchmark repo.
For SQL injection in insecure-js/server.js, user-controlled input reached a query string:
const query = `SELECT product FROM Orders WHERE orderNumber = ${postData.orderNumber};`;
const result = await sequelize.query(query, {
type: sequelize.QueryTypes.SELECT,
});For OS command injection in insecure-app/app.py, request input reached a shell command with shell=True:
cmd = request.form["command"]
process = subprocess.Popen(
cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE
)For XXE, the Flask app parsed user-controlled XML with DTD loading and entity resolution enabled:
xml_data = request.form["xml"]
parser = etree.XMLParser(load_dtd=True, resolve_entities=True)
tree = etree.fromstring(xml_data.encode(), parser)These are real findings. Aikido deserves credit for catching them.
What Corgea found that Aikido missed
The meaningful gap was coverage across the rest of the repository.
Corgea identified a data-modifying FastAPI endpoint with no authentication or authorization:
@app.put("/games/{game_id}")
def modify_game(game_id: int, updated_game: VideoGame):
for i, game in enumerate(video_games):
if game.id == game_id:
video_games[i] = updated_game
return {"message": "Game updated"}Corgea also found SSRF and open redirect paths:
@app.get("/fetch_url")
def retrieve_content(url: str):
response = requests.get(url)
return {"content": response.text}
@app.get("/redirect")
def navigate_to(next: str):
return RedirectResponse(url=next)In JavaScript, Corgea reported lodash template code injection:
const compiled = _.template(postData.template);
const output = compiled({});And it found exposed credentials outside the main application code, including Kubernetes deployment templates:
- name: AWS_ACCESS_KEY_ID
value: AKIA2JAPX77RGLB664VE
- name: AWS_SECRET_ACCESS_KEY
value: v5xpjkWYoy45fGKFSMajSn+sqs22WI2niacX9yO5This is where the benchmark moved from “which scanner is tidier” to “which scanner gives a team the issues it needs to fix.”
What Aikido found that Corgea missed
This was not a shutout. Aikido correctly reported several meaningful findings that were missing or less specific in the Corgea results.
It identified unsafe Java deserialization:
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(data));
Object deserializedObject = ois.readObject();It also identified disabled TLS verification:
response = requests.post(url, headers=headers, data=data, verify=False)And it reported a client-side HTML injection sink in the AI application UI:
resultContent.innerHTML = marked.parse(data.result);Those are real misses for Corgea. The difference is scale: Aikido missed 34 confirmed issues; Corgea missed 5.
The AI Code Audit cost problem
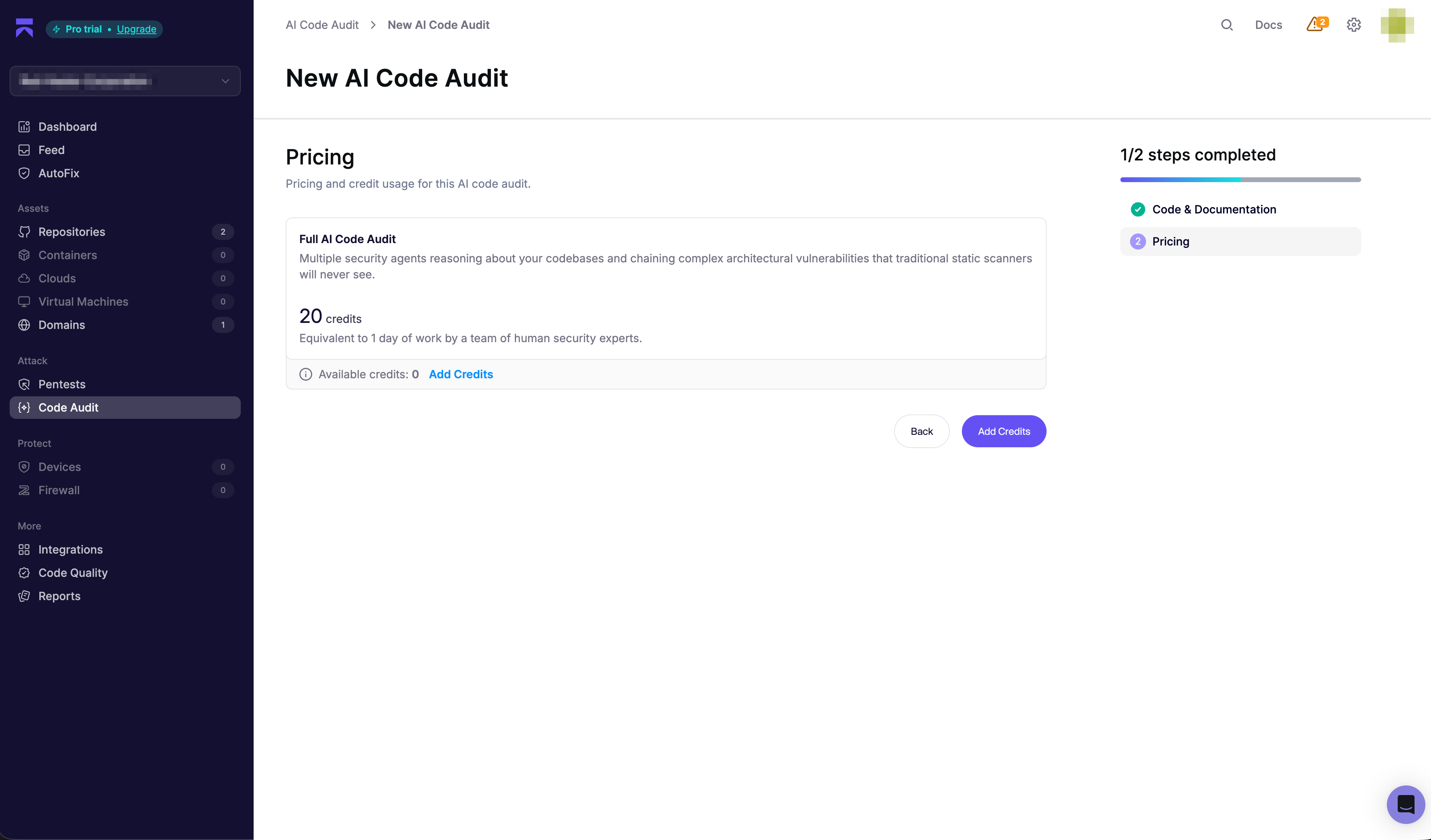
Aikido has a newer AI Code Audit product, but in the benchmark account it was metered separately from the normal SAST scan. The UI showed the full AI Code Audit for this repository at 20 credits. The purchase dialog showed credits costing $1 each, with a 100-credit minimum purchase.
That means this benchmark audit would have cost $20 on a per-run basis, with the account prompted toward a $100 credit purchase. Corgea’s AI SAST is included in the developer bundle.
That matters because the AI audit was being considered precisely where Aikido’s baseline SAST result was weakest. Paying per use for the deeper analysis is a hard tradeoff when the normal SAST scan found only 13 of 47 confirmed issues.
Aikido's AI Code Audit was metered separately in this run
The benchmark account showed a 20-credit AI Code Audit for this repository. At $1 per credit, that is $20 for the audit, with a 100-credit minimum purchase shown in the checkout dialog.
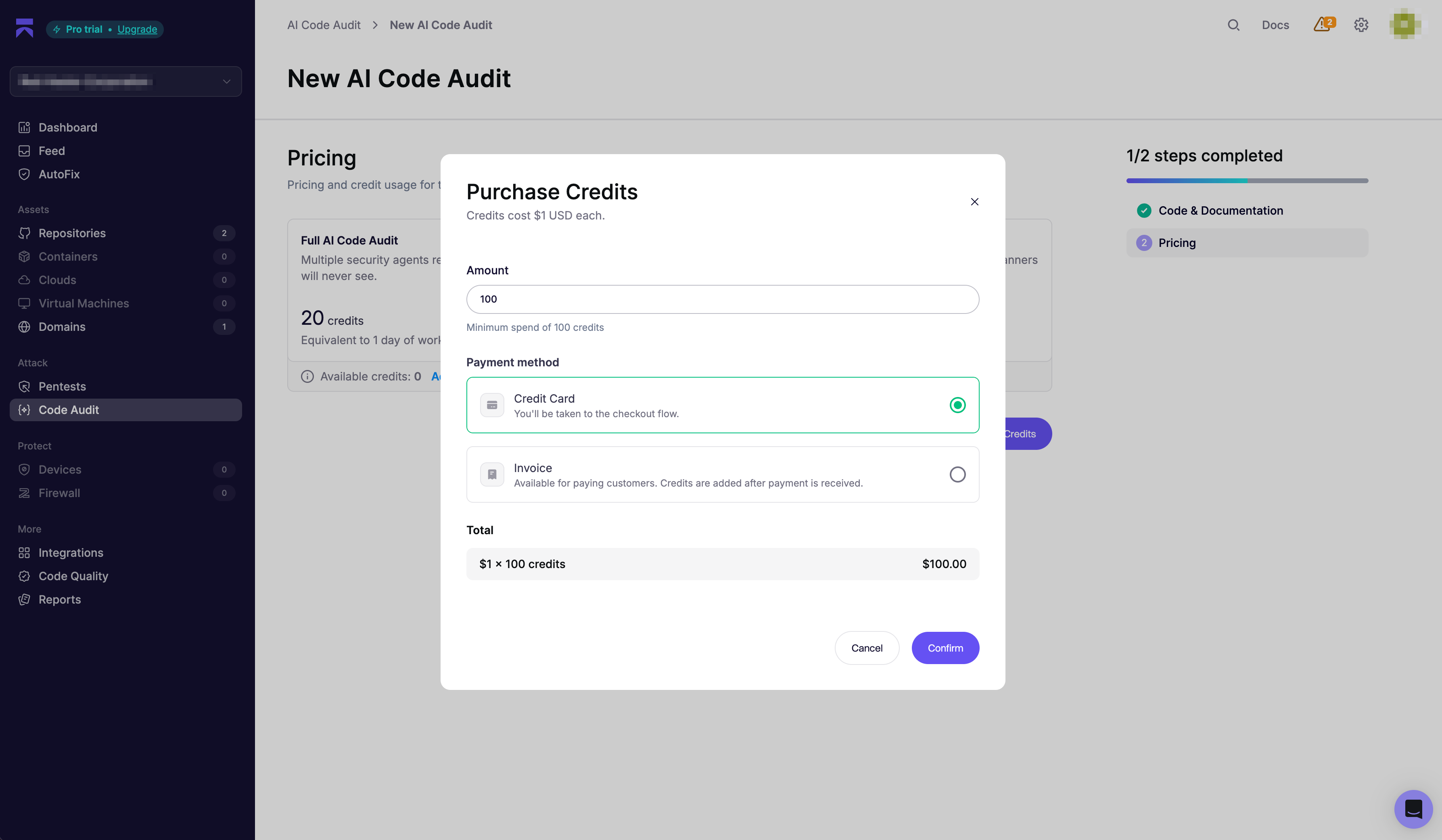
Cost notes are based on the Aikido in-product screens captured during the July 2, 2026 benchmark run.
Screenshot evidence from the run
The supplied screenshots are organized below into scan output and audit-cost evidence. The point is not that either UI looks better. The point is that the benchmark result and the cost model should be evaluated together.
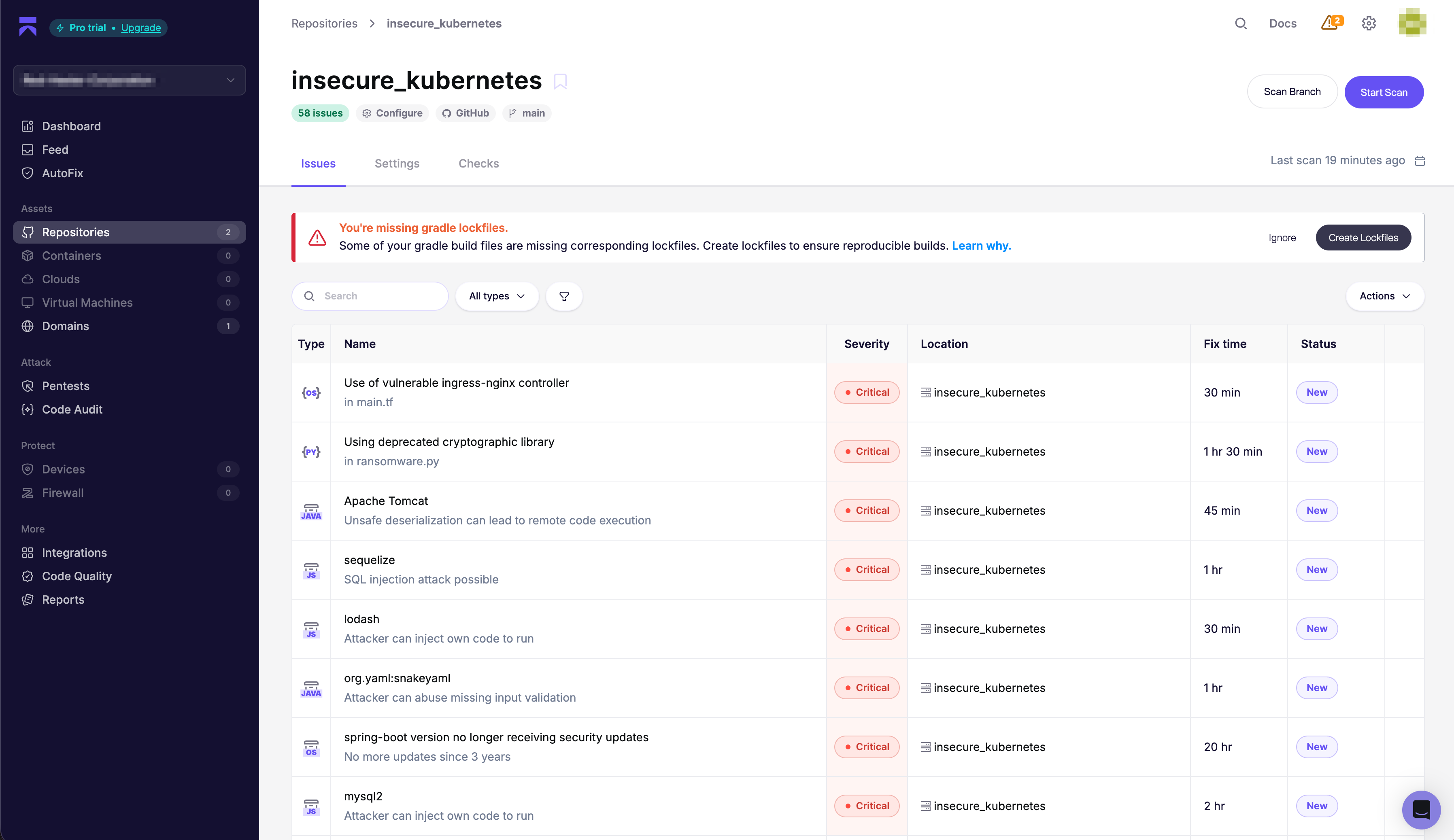
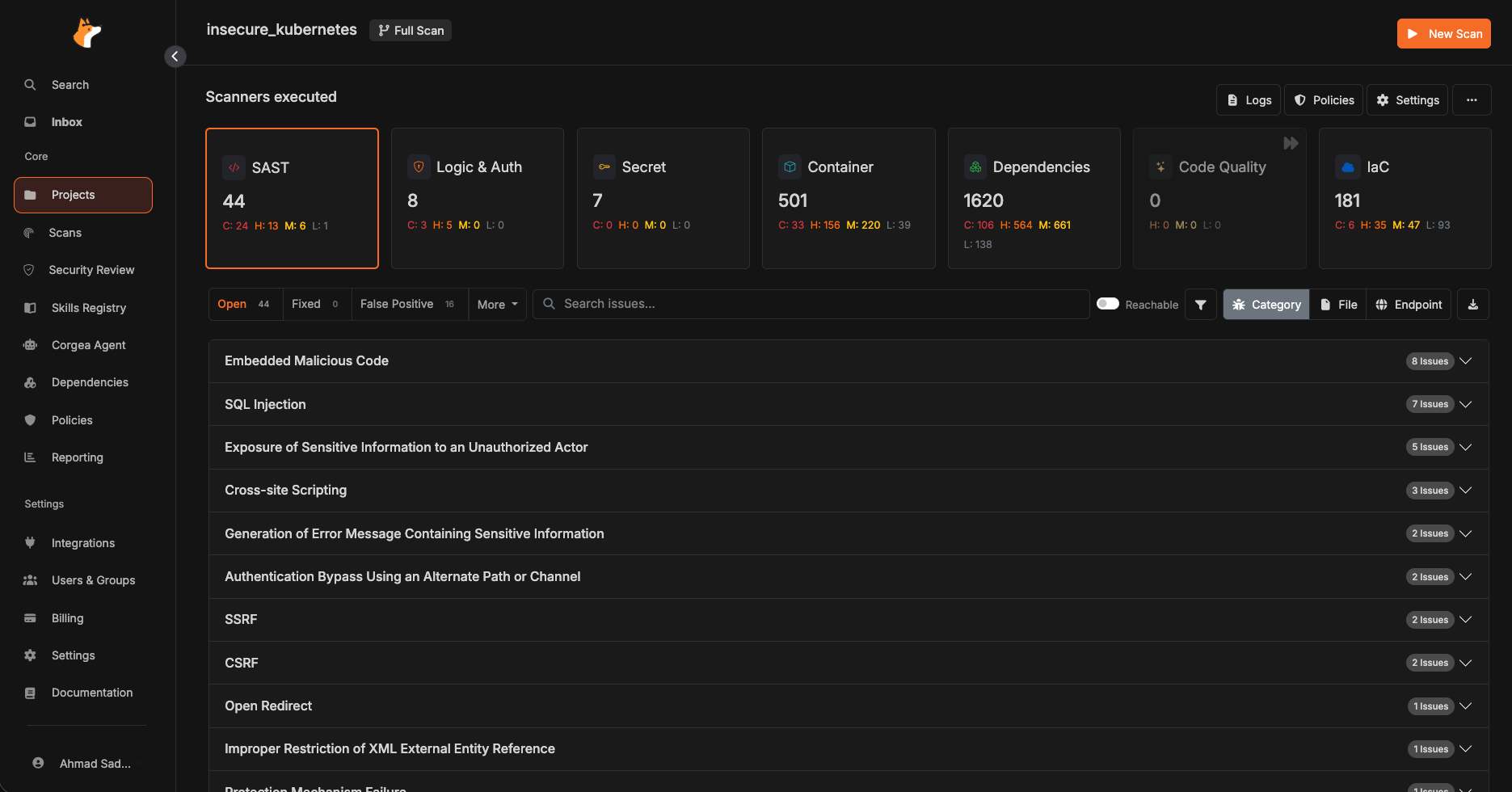
Side-by-side scan output from the benchmark
The screenshots below are organized around the benchmark narrative: Aikido's SAST issue list, then Corgea's scanner category view for the same deliberately vulnerable repository.
Recommendation
For this benchmark, Corgea is the stronger SAST performer. It found far more confirmed vulnerabilities, achieved much higher recall, and delivered the best F1 score.
Aikido’s output was cleaner and had slightly higher precision, so it may require less triage per reported finding. But that advantage did not offset the missed-vulnerability risk. A scanner that reports fewer incorrect issues but misses most confirmed issues leaves the security team with a false sense of progress.
If you are evaluating Aikido because you want broad all-in-one AppSec coverage, test its SAST depth separately. If your priority is finding and fixing real custom-code risk, run Corgea and Aikido on the same repositories, label the results against source, and score true positives, false positives, false negatives, recall, and F1.
On this repository, Corgea won.
Compare Corgea and Aikido on your own code
Run a pilot on a security-sensitive repository and measure confirmed findings, missed issues, fix quality, and total cost.
Corgea is not affiliated with Aikido. This benchmark reflects the repository, scan results, and product screens reviewed on July 2, 2026.